tree
-하나 또는 그 이상의 노드로 구성
-disjoint set (서로소 집합)
-subtrees 또한 tree
* 용어 정리
-노드의 degree : 노드의 가지 수
-트리의 degree : max{노드 degree} => 시간 복잡도
-트리의 높이/깊이(depth) : max{노드 레벨} => 공간 복잡도
-leaf node / non-leaf node : 말단 노드 / 말단이 아닌 노드
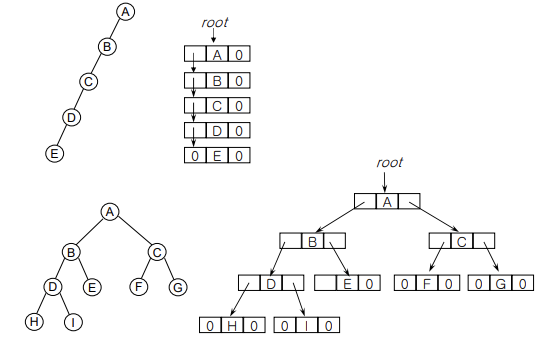
tree 표현 방법
1. list 표현
루트 노드 정보가 가장 먼저 나온 후 그 서브트리들의 리스트가 나옴
트리 노드의 데이터와 그 노드 자식들에 대한 포인터를 위한 필드 두 가지를 가지고 있는 메모리 노드 사용
본래 각 노드들의 자식 개수가 다르므로 포인트 필드 수는 가변적 메모리 노드가 적절
=> but, 노드 크기 고정이 데이터 표현 알고리즘에 적합 => 고정된 크기의 노드 사용 : 공간 낭비 ▲
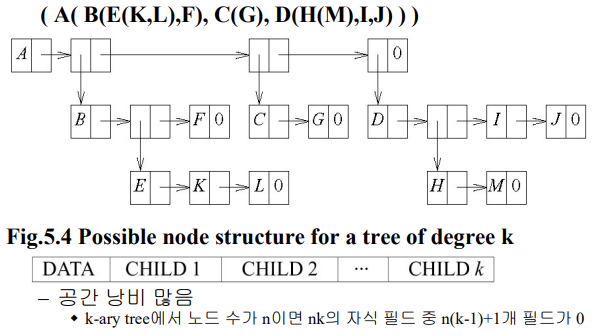
노드 크기 일정한 두가지 표현 방법 : 모두 각 노드마다 두 개의 링크 필드 or 포인터 필드 필요
2.왼쪽 자식-오른쪽 형제 표현
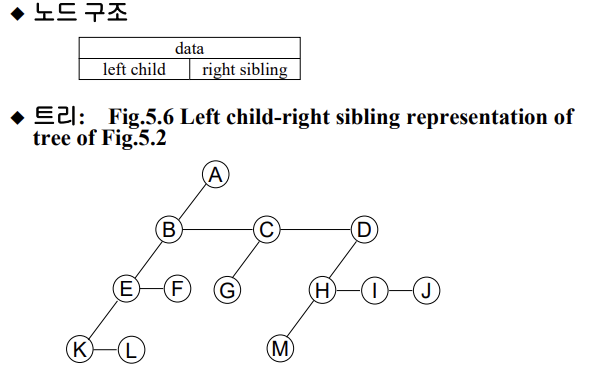
어떤 트리이든 binary tree로 변경 가능
3. 차수가 2인 트리 [이진 트리-binary tree]
왼쪽 자식-오른쪽 형제 표현에서 이진 트리 도출 가능
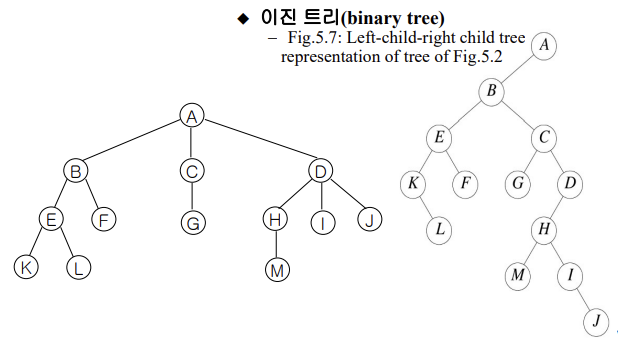
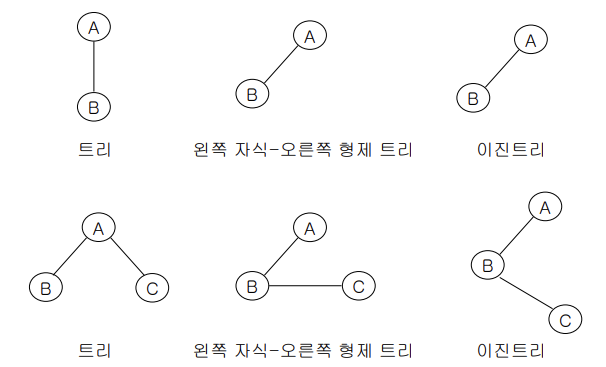
-empty tree 가능
-root + 2개 binary tree
-왼쪽 자식-오른쪽 형제 표현과 동일하게 right child인지 left child인지에 따라 의미가 다름
종류
-편향 이진 트리 (worst case)
-완전 이진 트리 (best case)
-포화 이진 트리
+각 레벨에서의 최대 노드 수를 알 수 있음 = 공간 복잡도 good
이진 트리 표현 방법
1. 배열 표현
1차원 배열에 노드 저장
: n개의 노드를 가진 완전이진트리
-parent(i) : [i/2]의 반내림(?) (if i !=1)
-leftchild(i) : 2i (if 2i<=n)
왼쪽 자식 없음 (if 2i>n)
-rightchild(i) : 2i+1 (if 2i+1<=n)
오른쪽 자식 없음 (if 2i+1>n)
: 완전 이진 트리 = 낭비되는 공간 없
: 편향 트리 = 공간 낭비 ㅇㅇ
-배열의 경우, 0은 비우고 root = 1

2. 링크드 리스트 표현 (chain)
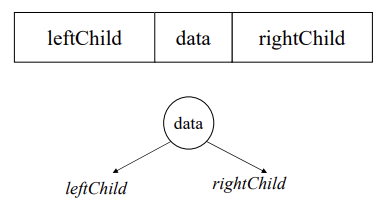
- 노드 표현
parent를 알기 힘들어 parent 필드 추가
= linked list는 root만 알면 각각의 parent를 알 수 있음

이진 트리 순회와 트리 반복자
트리 순회 (tree traversal)
트리의 모든 노드를 한 번씩만 방문 //stack 사용
LR기준 : inorder(LVR), preorder(VLR), postorder(LRV)
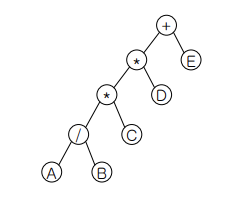
inorder : 더 이상 왼쪽 자식 없을 때까지 왼쪽으로 이동한 후 (왼쪽 자식이 없을 경우) 해당 노드의 루트 방문 후 오른쪽 자식으로 이동(동일하게 왼쪽 자식 없으면 본인 방문 후 오른쪽 자식 방문) 반복
: 왼쪽 자식 방문 => 루트 방문 =>오른쪽 자식 방문
A / B * C * D + E
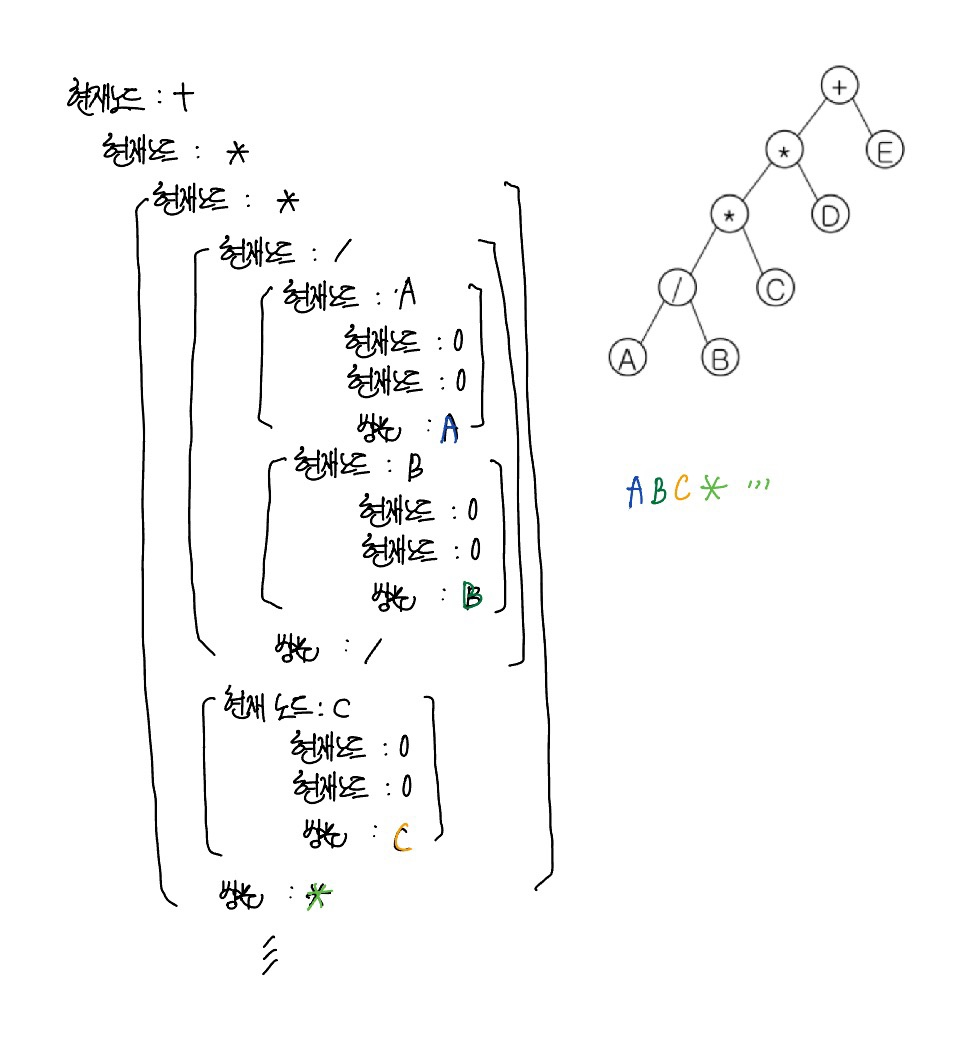
preorder : 노드 먼저 방문 후 왼쪽 자식으로 이동, 더 이상 왼쪽 자식이 없을 경우 오른쪽 자식 방문하여 반복
: 루트 방문 => 왼쪽 자식 방문 => 오른쪽 자식 방문
+ * * / A B C D E
=> root이 가장 먼저 출력됨
postorder : 왼쪽 자식 먼저 쭉 방문 후 없을 경우 오른쪽 자식 방문하고 root로 돌아옴 반복
: 왼쪽 자식 방문 =>오른쪽 자식 방문 => 루트 방문
A B / C * D * E +


레벨 순서 순회(level order traversal)
: 각 레벨 별로 루트 방문 => 왼쪽 자식 방문 => 오른쪽 자식 방문 //Queue 사용
+ * E * D / C A B
우선순위 큐 (priority Queue)
//like 기계 대여
= 사용자들의 사용 시간은 동일하고 각자 제시하는 가격이 다른 경우, 가장 높은 가격 제시하는 사용자에게 우선 순위 부여
우선 순위가 가장 높은 (낮은) 원소 먼저 삭제
-최대 우선순위 큐 (A max priority queue)
표현 방법
| 무선형 순서 리스트 | 최대 히프 (max heap) | ||
| IsEmpty() : | O(1) | O(1) | |
| Push() | O(1) | O(log n) | |
| Top() | theta(n) | O(1) | |
| Pop() | theta(n) | O(log n) | |
: 최대 히프 조건 = 1) 최대 트리 - 각 노드의 키 값 >= 자식의 키 값 , 2) 완전 이진 트리 - 삽입 할 자리가 정해져있음
즉, 최대 트리이면서 완전 이진 트리여야함 => 삽입, 삭제가 이루어져도 이 조건은 만족해야함
=> top의 원소가 가장 우선순위 높은 원소
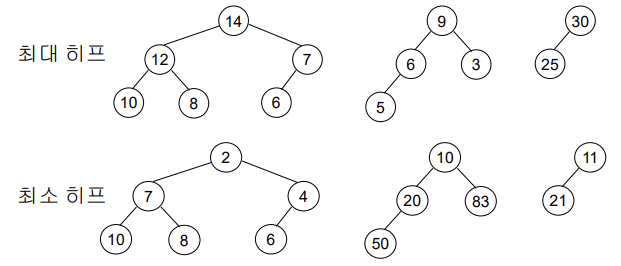
최대 히프에서의 삽입
-정해진 삽입 장소에서 부모 원소와 비교를 통해 최대 트리의 조건을 만족하도록 배치
최대 히프에서의 삭제
-루트가 우선순위 가장 높은 원소이므로 루트 삭제
-마지막 위치 노드를 루트 위치로 가져온 후 노드 수 1 감소
-최대 트리 조건을 만족하도록 재배치(두 child 중 큰 값보다 작으면 두 값 교환 = 반복)
이원 탐색 트리 (binary search tree)
dictionary 사용 : pair <키, 원소>의 집합
이원 탐색 트리의 조건
-모든 원소는 서로 다른 키를 가짐
-왼쪽 서브트리 키 < 그 루트의 키
-오른쪽 서브트리 키 > 그 루트의 키
위 조건은 이원 탐색 트리의 모든 서브트리에도 적용 //삽입, 삭제 시 주의해야함
이원 탐색 트리의 삽입
-x의 key값을 가진 노드 탐색
-탐색 성공 = 원소 변경
-탐색 실패 = 탐색이 끝난 지점에 쌍 삽입
이원 탐색 트리의 삭제
1) leaf-node의 경우 (child = 0)
부모의 자식 필드에 0 삽입 후 삭제된 노드 반환
2) non-leaf & child 1개
-삭제된 노드의 자식을 삭제된 노드의 자리에 위치
3) non-leaf & child 2개
-왼쪽 서브트리의 최대 원소 or 오른쪽 서브트리의 최소 원소로 대체
-이원 탐색 트리의 조건에 맞도록 재배치
=> 이원 탐색 트리(n)의 높이
최악의 경우 : 편향 이진 트리 = 이원 탐색 트리 높이 n
평균 이원 탐색 트리 높이 = O(log n)
포리스트 (forest)
-n(>=0)개의 disjoint 트리들의 집합

Disjoint set의 트리 표현
집합의 모든 원소 수 0,1,2,...,n-1
자식에서 부모로 가는 링크로 연결
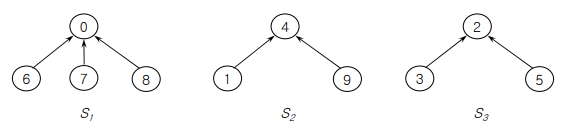
S1={0,6,7,8}
S2={1,4,9}
S3={3,2,5}
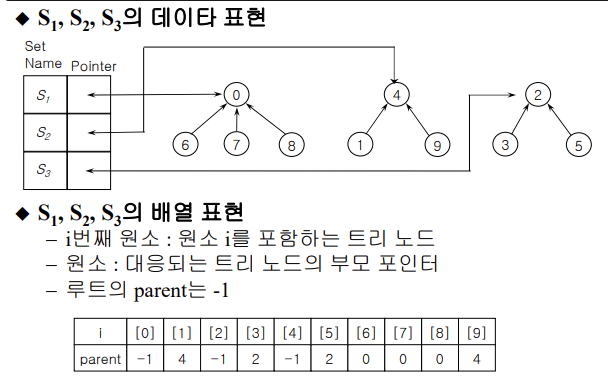
각각의 집합 구분에 root parent 사용
root parent = [-1]
disjoint set들의 union
Si U Sj => 두 트리 중 하나를 다른 트리의 서브트리로 넣음

SimpleUnion과 SimpleFind
-변질 트리
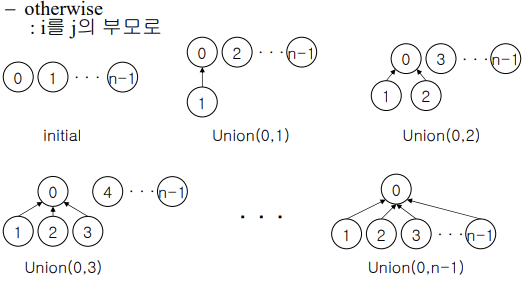
n개의 노드가 각각 n개의 집합에 하나씩 포함됨 : n개 노드로 이루어진 포리스트
: parent[i] = -1
: Union(0,1), Union(1,2), Union(2,3),,,Union(n-2,n-1)

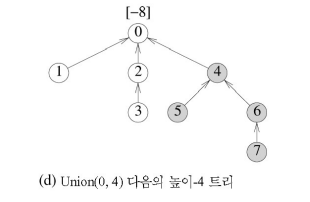
=> weighting rule을 적용한 합집합
union(i,j)를 위한 가중 규칙
: 루트 i를 가진 트리의 노드 수 < 루트 j를 가진 트리의 노드 수 => j를 i의 부모로!


'학교 > 자료구조' 카테고리의 다른 글
| [자료구조] 5장 실습 코드 정리 : PQ&Maxheap (minheap이라면?) (0) | 2023.05.24 |
|---|---|
| [자료구조] 5장 헷갈리는 개념, 코드 정리 BST, Tree Traversal (0) | 2023.05.21 |
| [자료구조] toslide 정리 (0) | 2023.04.19 |
| [자료구조 실습 코드] (0) | 2023.04.17 |
| [배열과 구조체] kmooc 자료구조 (0) | 2023.03.19 |