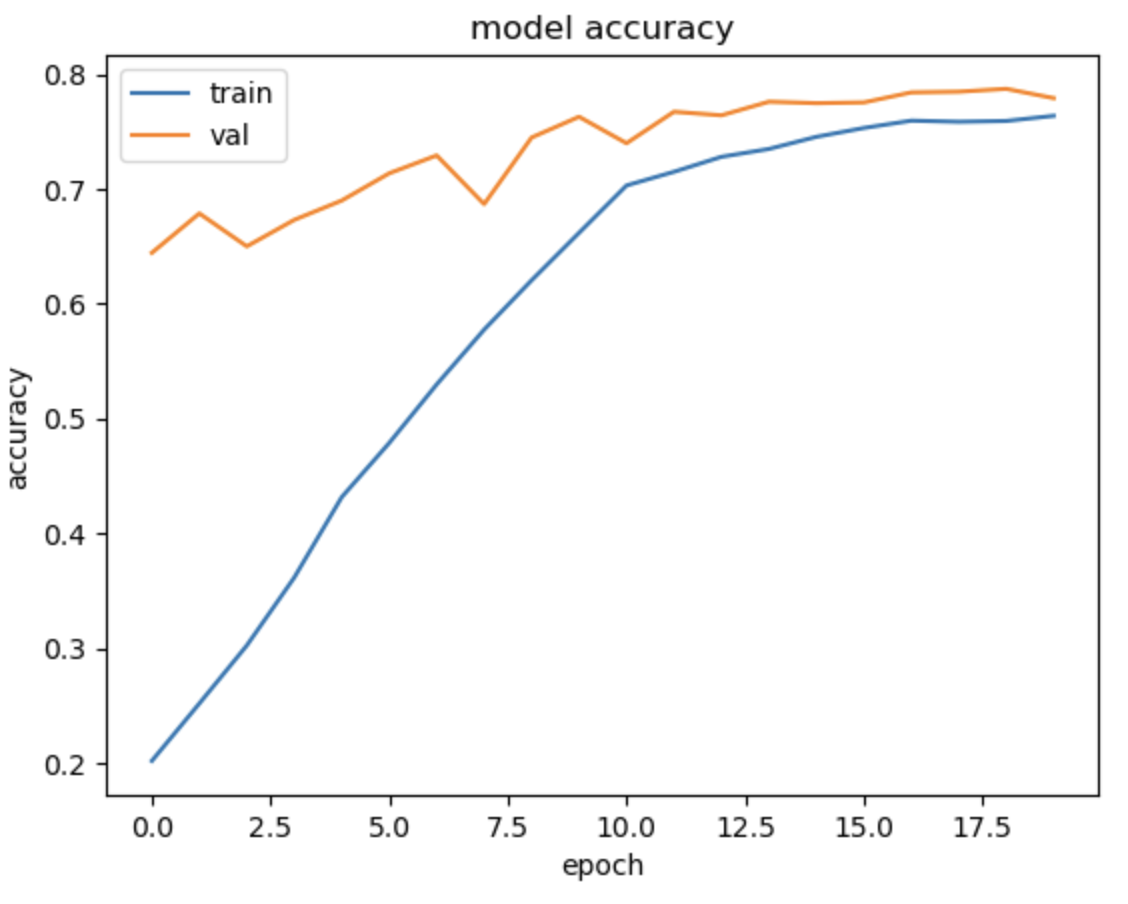
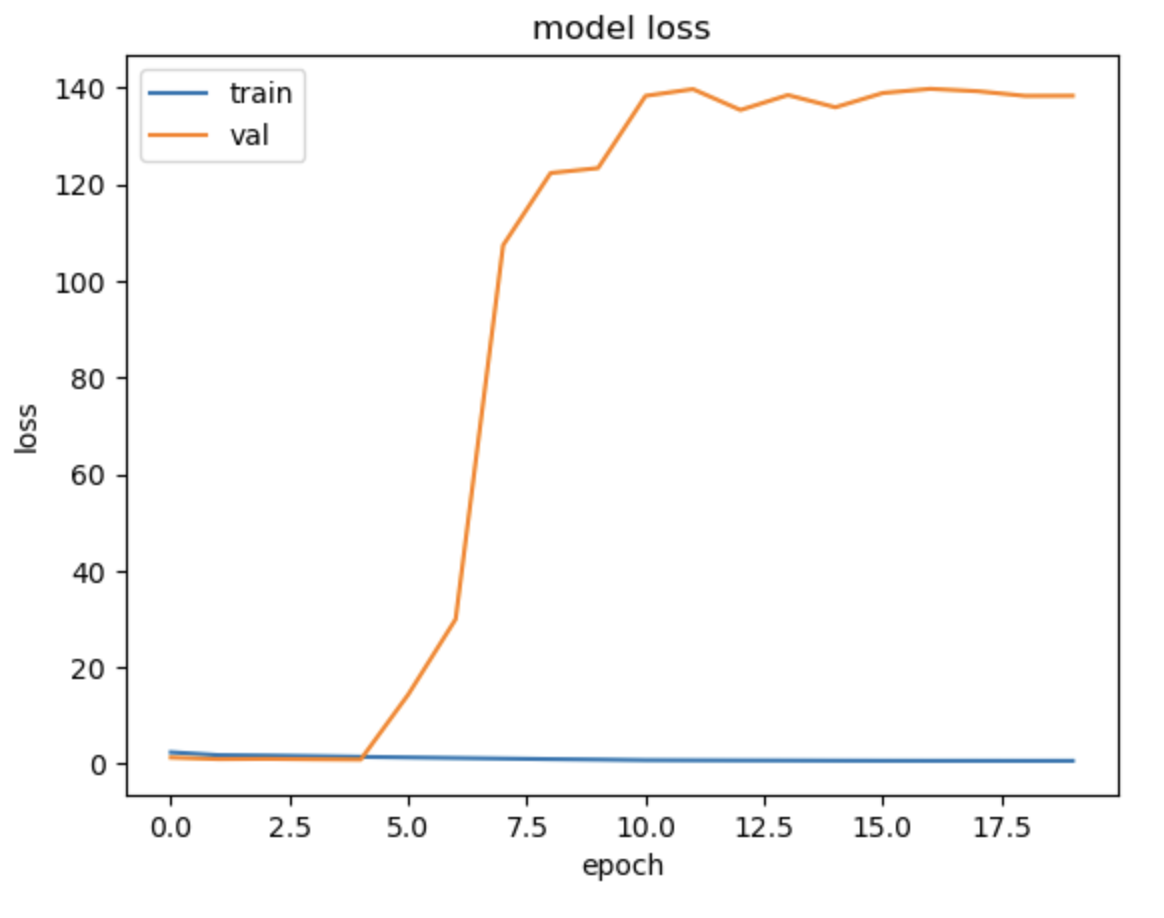
현재 ham 10000 데이터로 cnn 학습시켜둠
이때 성능이 생각보다 떨어짐을 알 수 있음
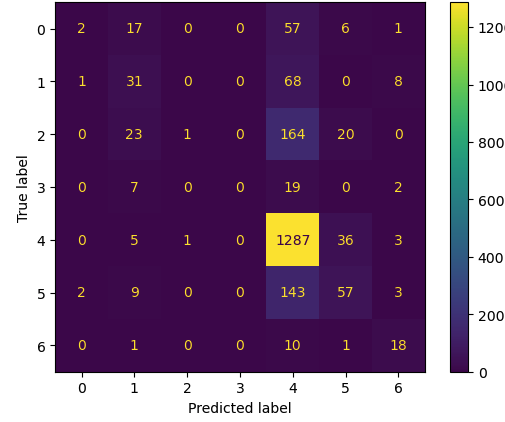
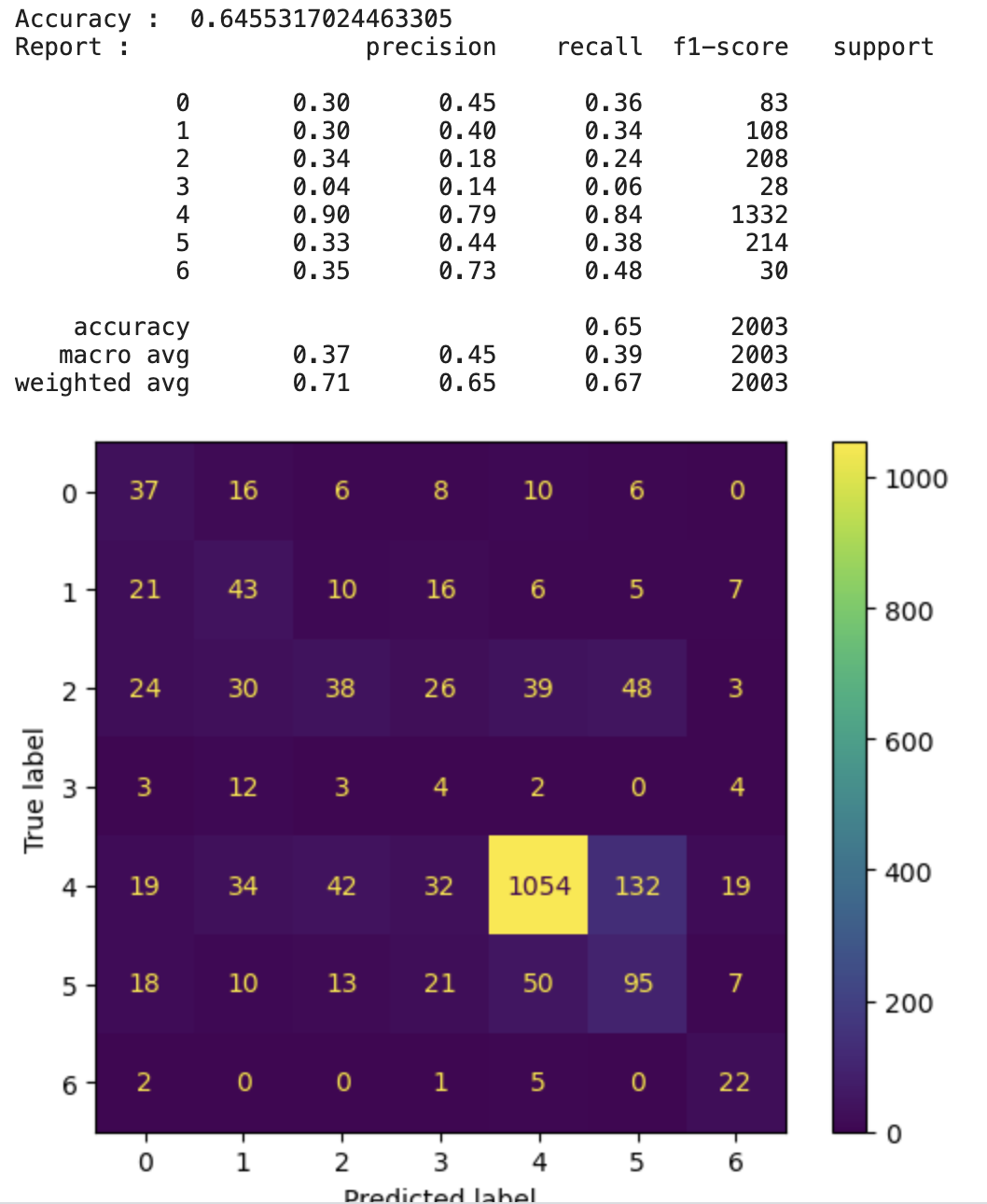
그 이유로 데이터 불균형이 있음 //위 confusion metrix를 보면 알수있다시피 label 4의 정확도만 큼
그 이유는 label 4 데이터가 가장 많이 있기 때문
나머지 label은 학습하기에 데이터가 충분하지 않다.
그래서 overfitting으로 해결해보기로 함
※oversampling 시 주의점
-data augmentation과 동일하게 train 데이터에만 적용해야함
-data split (train, test, valid) 후 train에만 적용하면 됨
1) 무식하게 말 그대로 데이터 개수가 가장 많은 label에 맞춰 다른 label들의 데이터 개수를 늘리는 것
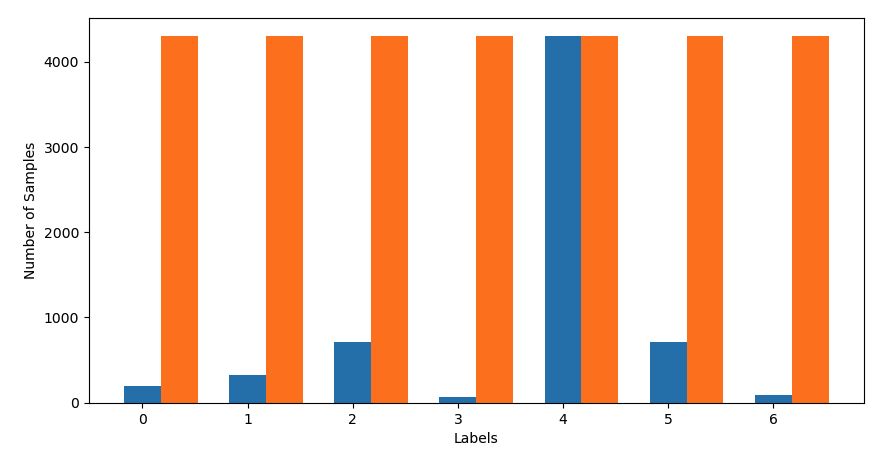
위에 oversampling 전후 데이터 양을 보면 예상할 수 있다시피 과적합 일어나는게 당연하다,,,

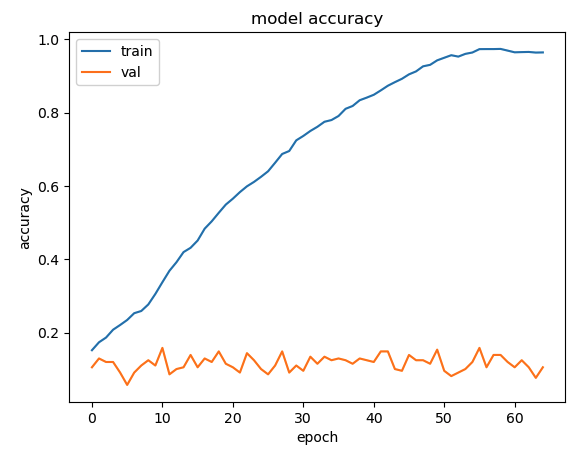
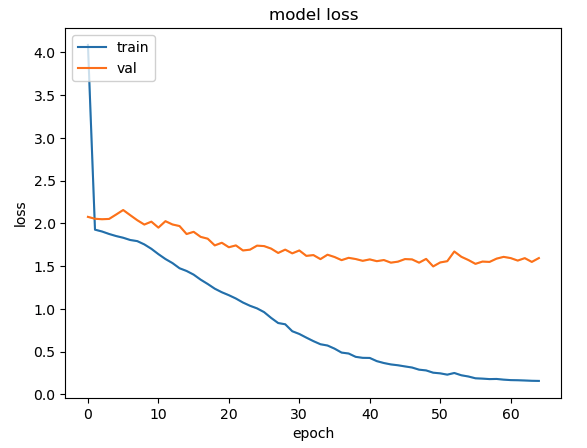

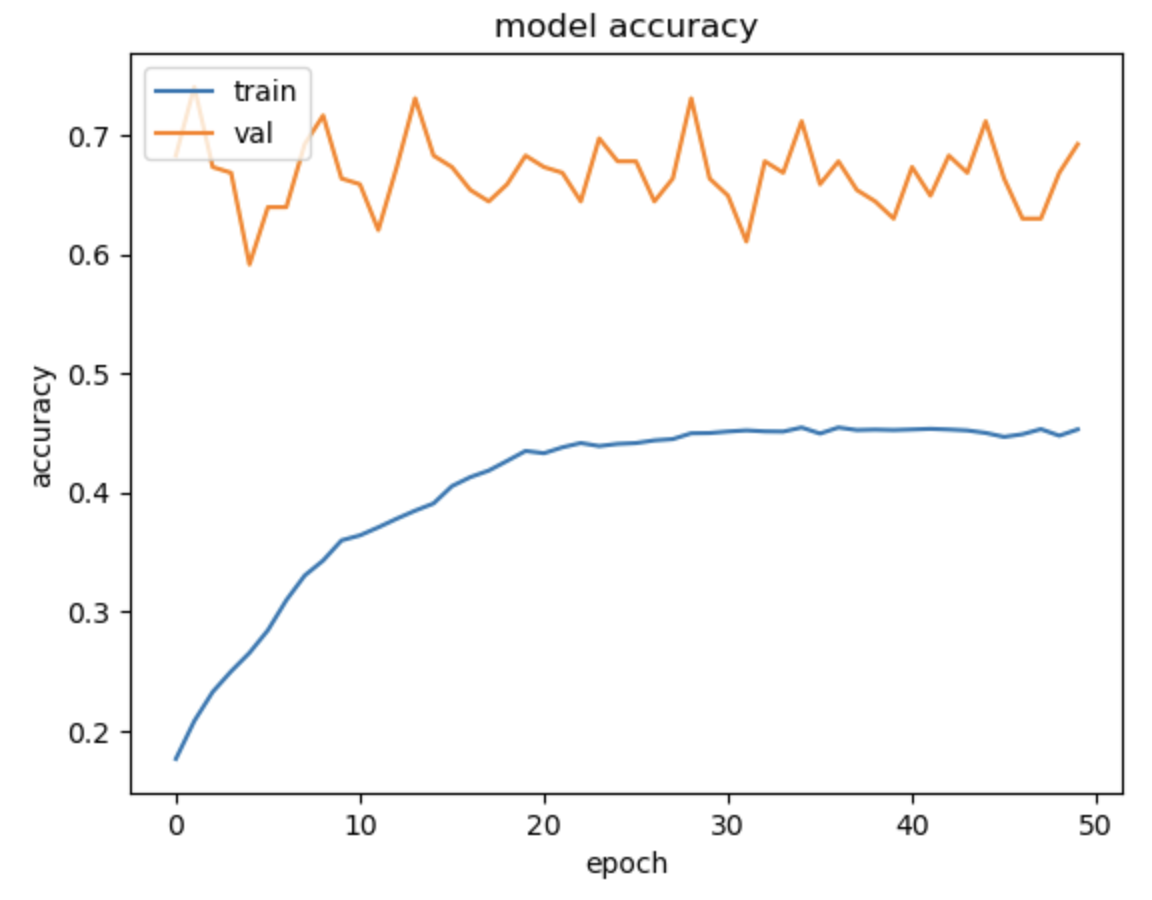
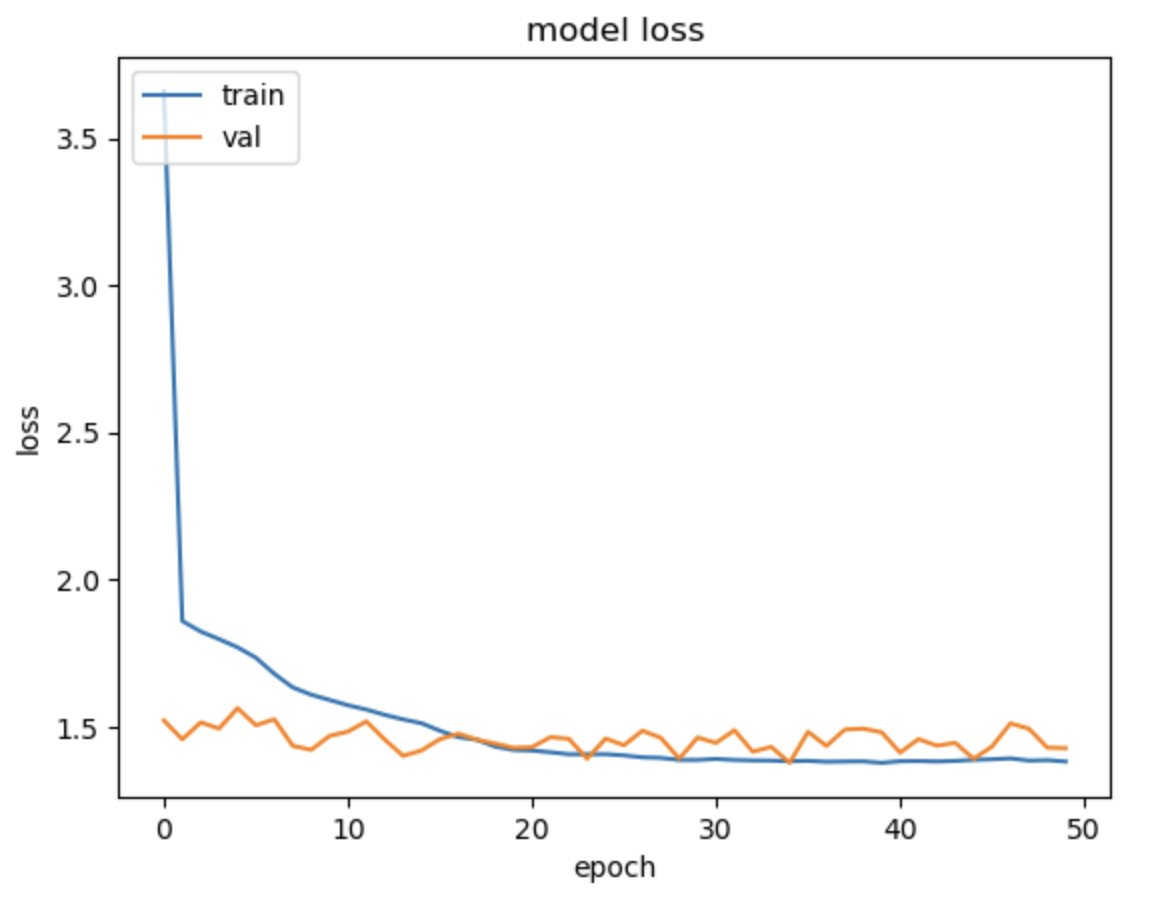
이때는 잘 몰랐는데 그래도 무식한 oversampling 적용한 결과가 기존 cnn 학습보다 성능이 훨 좋아지긴 함
기존엔 label 4만 구분할 수 있는 수준이었다면 지금은 그래도 다른 label들도 조금은 학습이 되니,,
2) smote 적용
smote는 oversampling의 가장 유명한 방법이라고 한다.
진짜 간단하게 설명하자면 적은 양의 데이터를 분포를 찍고 그 사이사이 점을 찍어 새로운 데이터들을 생성해냄

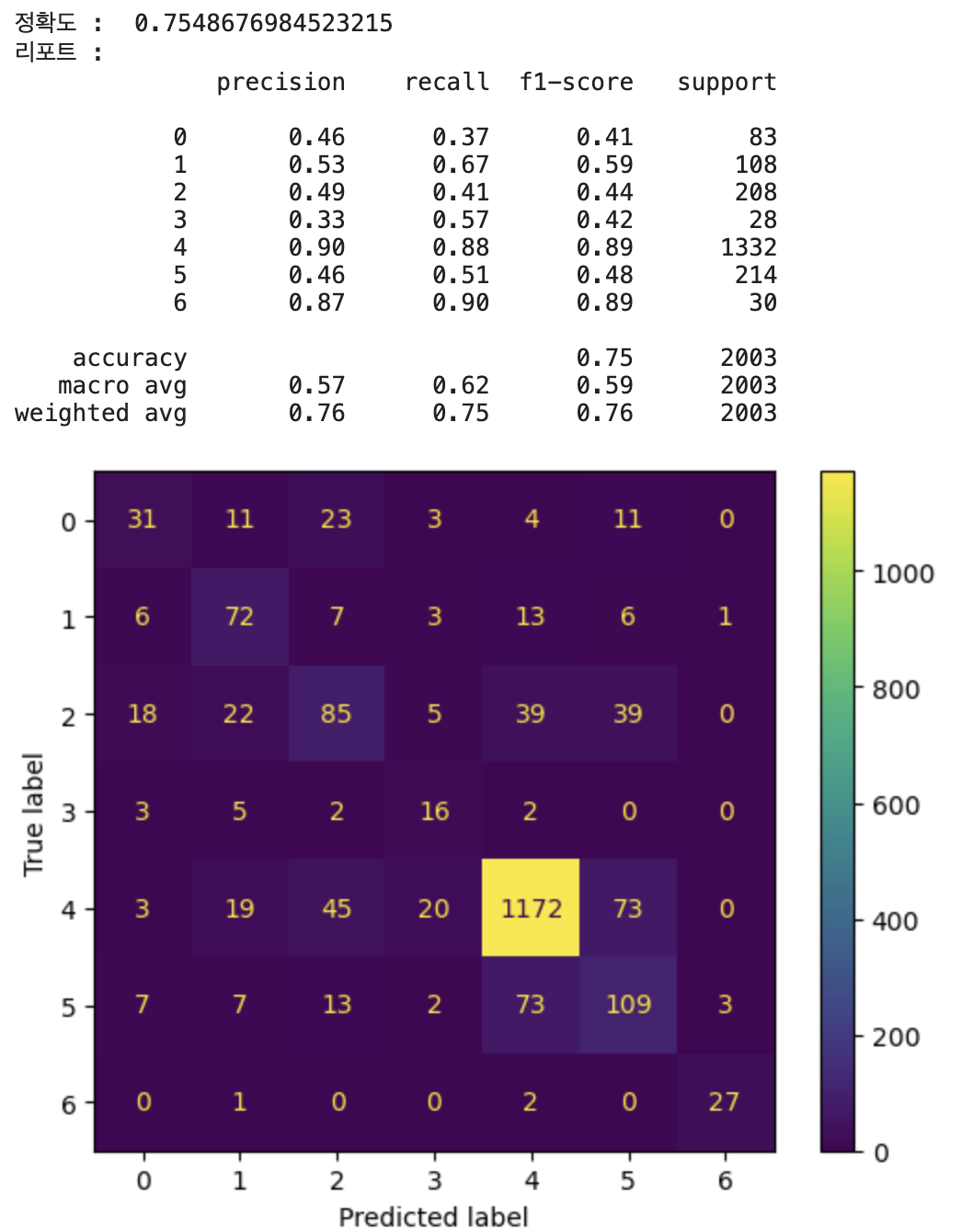
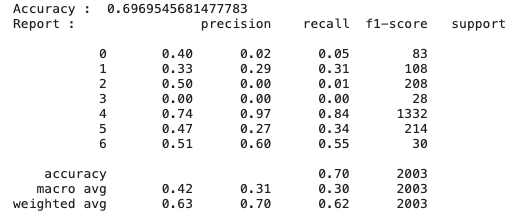
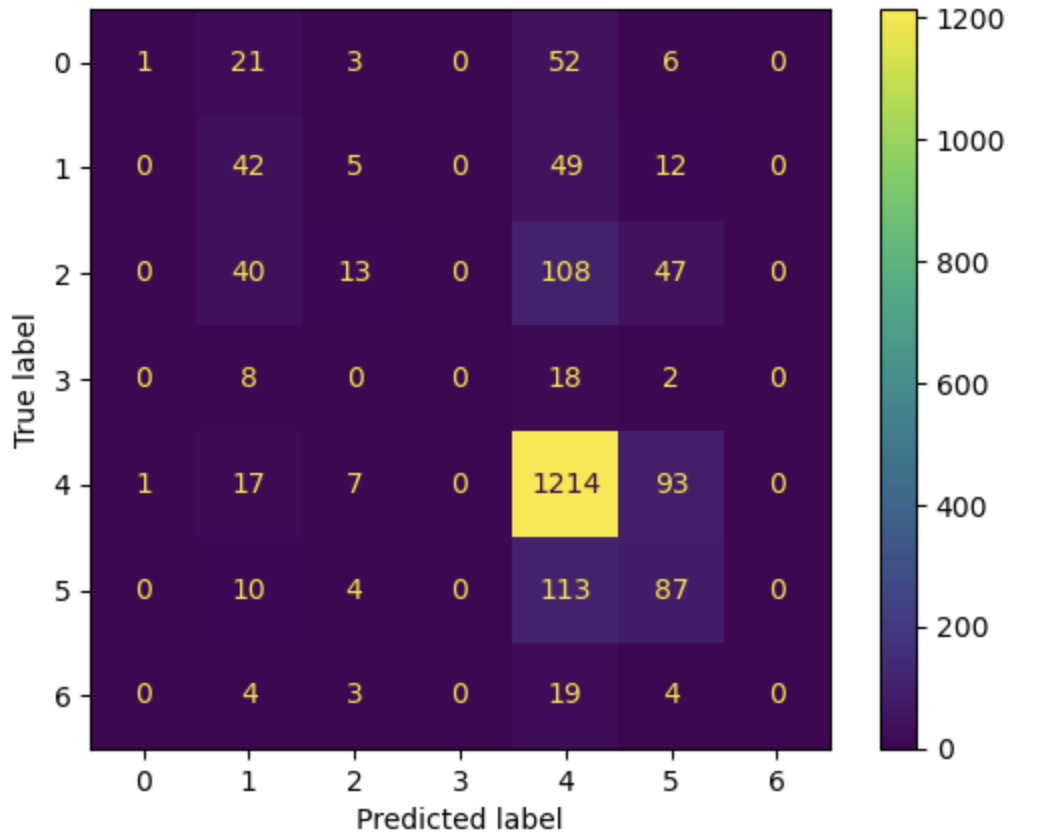
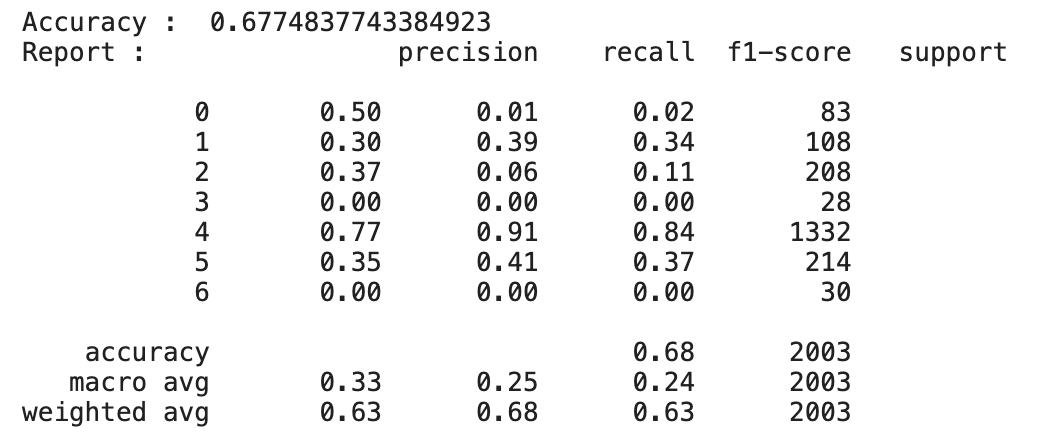
이게 정확도는 기존 cnn 학습 정확도와 그렇게 많이 차이가 나진 않지만 이런 imbalance data classification에서는 정확도로만 판단하면 안됨
(정상 : 비정상 = 9:1의 경우 다 정상으로 판단했을때 성능이 0.90임)
=> 그렇기때문에 imbalance classification의 경우 recall과 precision을 살펴봐야함
이 두 지표를 확인해보았을때 smote를 적용한 결과가 훨씬 유의미함을 알 수 있음
+label 3과 6의 경우 원본 데이터의 개수는 거의 비슷한데 결과가 6은 classification이 잘되는 반면 3은 잘 안되는 것을 보아 label 6보다 다른 데이터와 비교적 비슷하다는 것을 유추해볼 수 있음
그래도 그냥 막 oversampling 적용한 것에 비해 smote 적용한 것의 결과가 3에서 더 좋음을 알 수 있다
'DL' 카테고리의 다른 글
| [RNN, LSTM, GRU] (1) | 2023.10.02 |
|---|---|
| [구강암 배경지식] 명의 (0) | 2023.09.26 |
| 후두암 AI 회의록 (0) | 2023.09.06 |
| [Oral cancer detection] 논문 정리 (0) | 2023.08.14 |
| [Automated Detection and Classification of Oral Lesions Using Deep Learning for Early Detection of Oral Cancer] (0) | 2023.08.03 |
