RNN : recurrent neural networks
순환 신경망으로 입력과 출력을 시퀀스 단위로 처리하는 방법
: 순서가 있는 데이터
ex) 시계열 데이터, 텍스트 데이터
-다대일 모델링 : 입력 데이터가 시퀀스 (ex) 감성분석 : 텍스트데이터 => 감성 클래스 분류)
감성분석 : (sentiment analysis : opinion mining) : 태도, 의견, 성향 등 주괁적 데이터 분석 NLP
-일대다 모델링 : 출력 데이터가 시퀀스 데이터 (ex) 이미지 캡셔닝 : 이미지데이터 => 텍스트 데이터)
-다대다 모델링 : 입력, 출력 데이터 모두 시퀀스 데이터
(ex) 비디오 분류 : 비디오데이터 => 시간 순 비디오 분류라벨)
(ex) 번역 : 한 언어의 텍스트 데이터 => 다른 언어의 텍스트 데이터) //챗봇, 번역



시퀀스 데이터는 MLP와 CNN이 처리할 수 없음 => 입력 샘플의 순서를 다루지 못하기 때문
위 두 모델은 가중치가 샘플 처리 순서와 상관없이 업데이트됨
따라서 시퀀스 데이터는 일반 신경망 모델이 아닌 RNN 모델에서 처리할 수 있음
RNN 구조
기본 신경망에서는 정보를 입력층에서 은닉층으로 전달 후 출력층으로 전달
RNN,순환 네트워크에서는 은닉층이 입력층와 이전 타임 스텝의 은닉층으로부터 정보 전달받음 //2개의 입력 존재
=> 인접 타임 스텝의 정보가 은닉층에 존재해 네트워크가 이전 이벤트를 기억할 수 있음
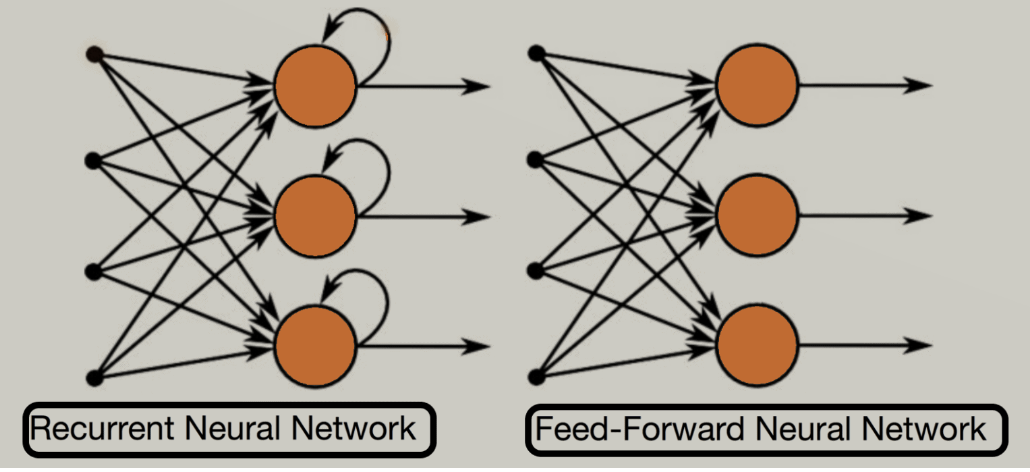


1) 현재 입력층에서의 입력
2) 같은 은닉층에서의 t-1 타입 스텝의 활성화 출력
2개의 입력 존재 : x(t) & h(t-1)
x = (입력값*해당층 가중치)
+ (t-1 타임스텝 활성화 출력 * 전달 시 가중치)
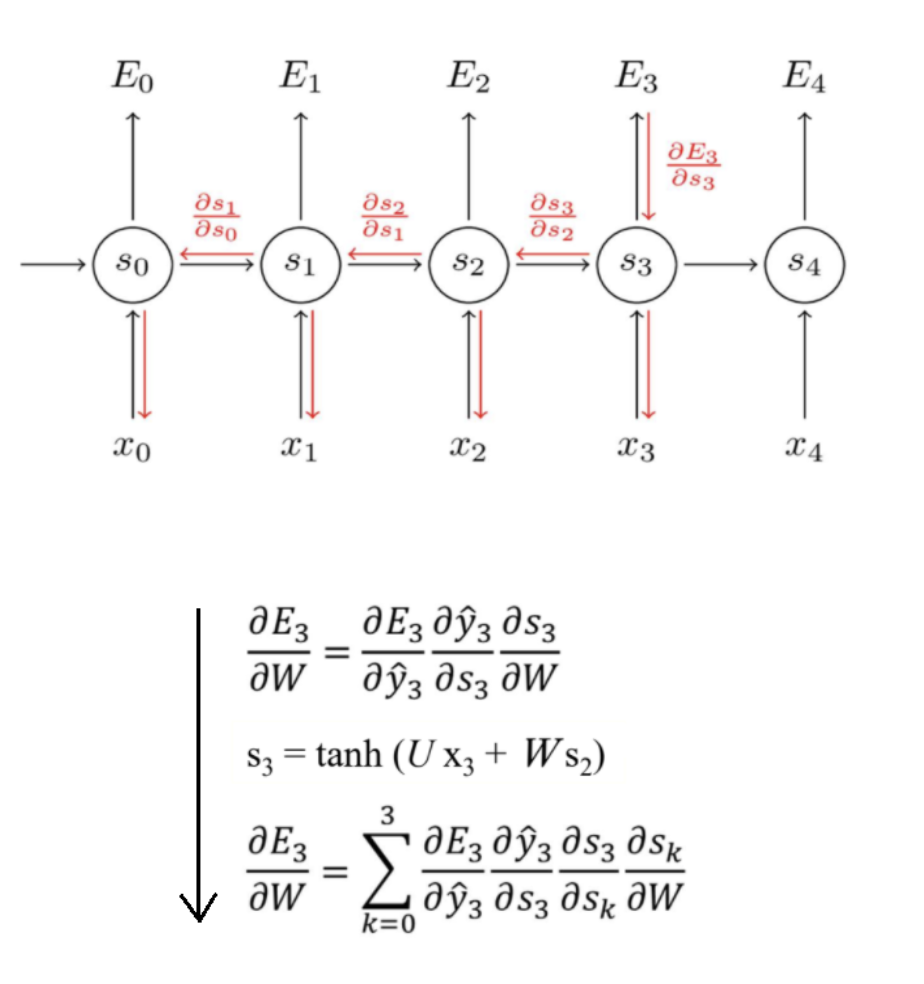
BPTT : back propagation through time
재귀적 형태의 모델을 시간에 대해 펼쳐서 현재 시점의 에러를 최초 시점까지 전파해 학습하는 모델
back propagation의 확장
RNN의 문제점
-기울기 소실 : gradient vanishing (역전파 과정에서 입력층으로 갈 수록 기울기가 점차적으로 적어짐)
-기울기 폭주 : gradient exploding (기울기가 점점 커지는 과정에서 가중치들이 비정상적으로 큰 값이 되어 발산함)
위 RNN의 문제점을 보완하기 위해 T-BPTT와 LSTM
T-BPTT : truncated back propagation through time
LSTM : long short-term memory
LSTM : 바닐라 RN의 장기 의존성 문제의 보완모델
vanishing gradient problem 보완
RNN의 hidden state에 cell-state 추가한 구조
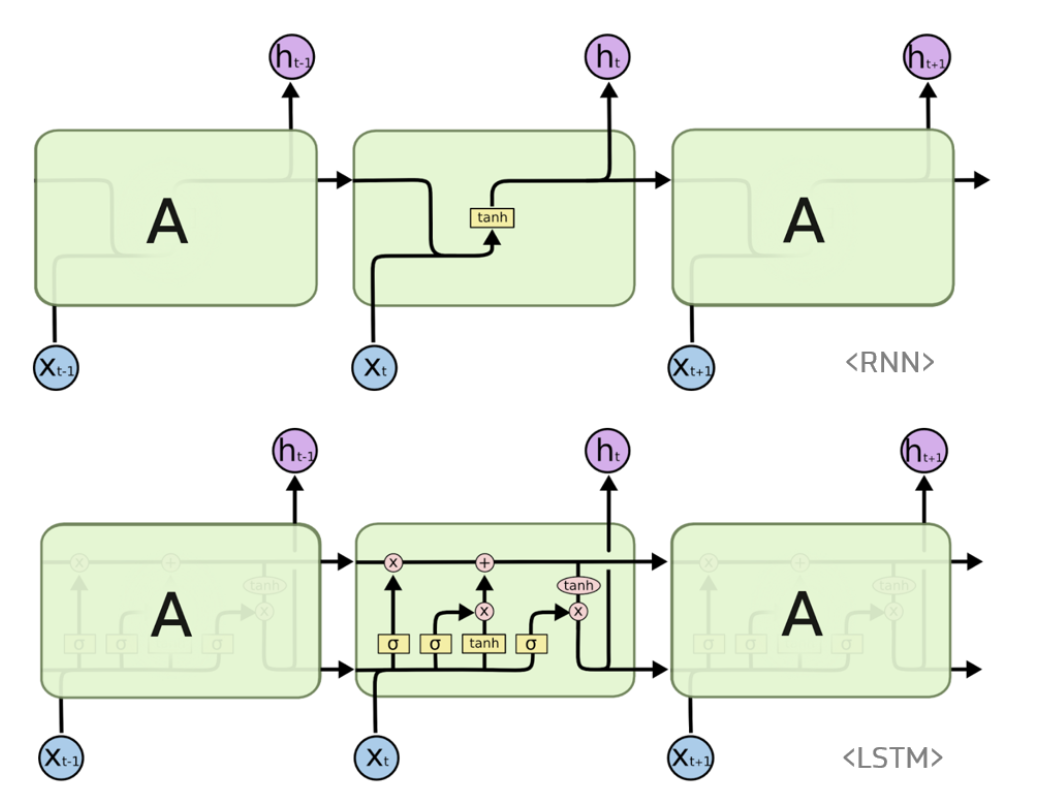
cell state : 일종의 컨베이어벨트 역할
은닉층 메모리셀에 삭제, 입력, 출력 게이트 추가
state가 오래 경과되더라도 gradient 전파가 수월
//필요하지 않은 기억은 지우고, 기억해야할 정보는 저장함

- 이전 시점 장기 기억 c(t-1)이 삭제 게이트를 지나 sigmoid 0/1 값에 따라 삭제 선택됨
- 삭제될 부분이 삭제된 장기기억 셀에 g(t)가 입력 게이트를 지나며 정해진 중요한 부분을 덧셈 연산을 통해 저장
- 만들어진 c(t)는 추가 변환 없이 바로 출력
- 2에서 만들어진 셀이 tanh함수로 전달되고 출력 게이트에 의해 걸러지며 다음 h(t) 단기 상태로 전달됨
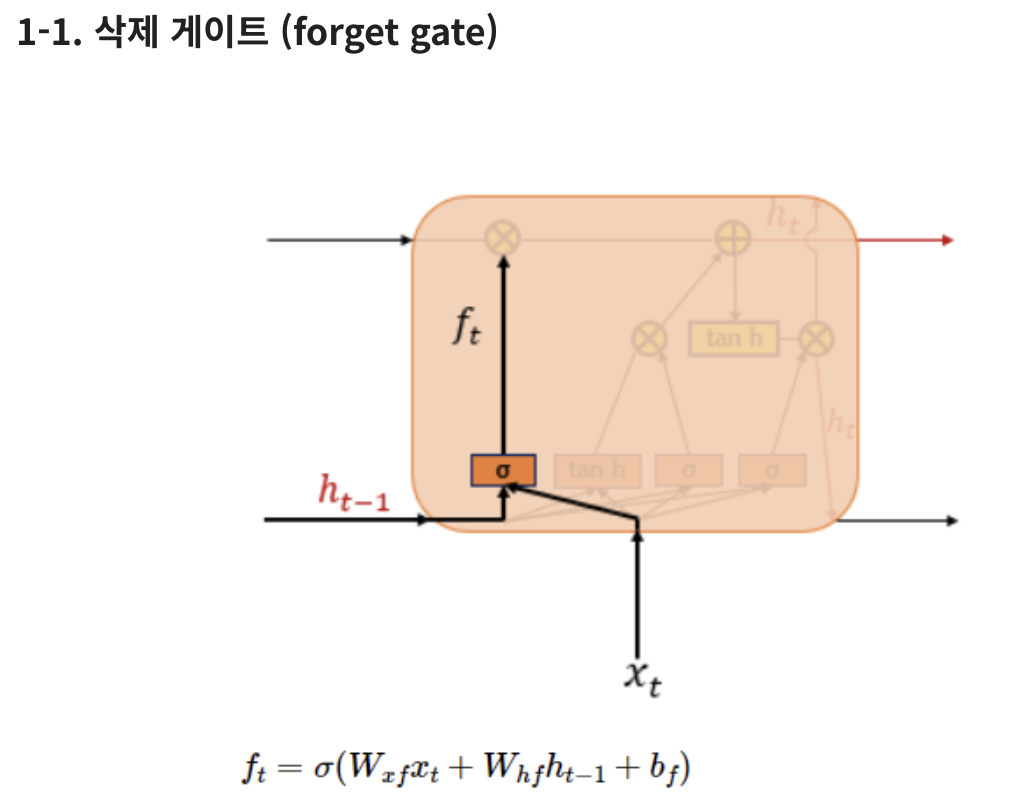
1-1) 현재 시점의 입력 x와 이전 시점의 은닉 상태가 sigmoid 함수를 지남
그 결과 도출된 0/1 값에 따라 삭제 결정
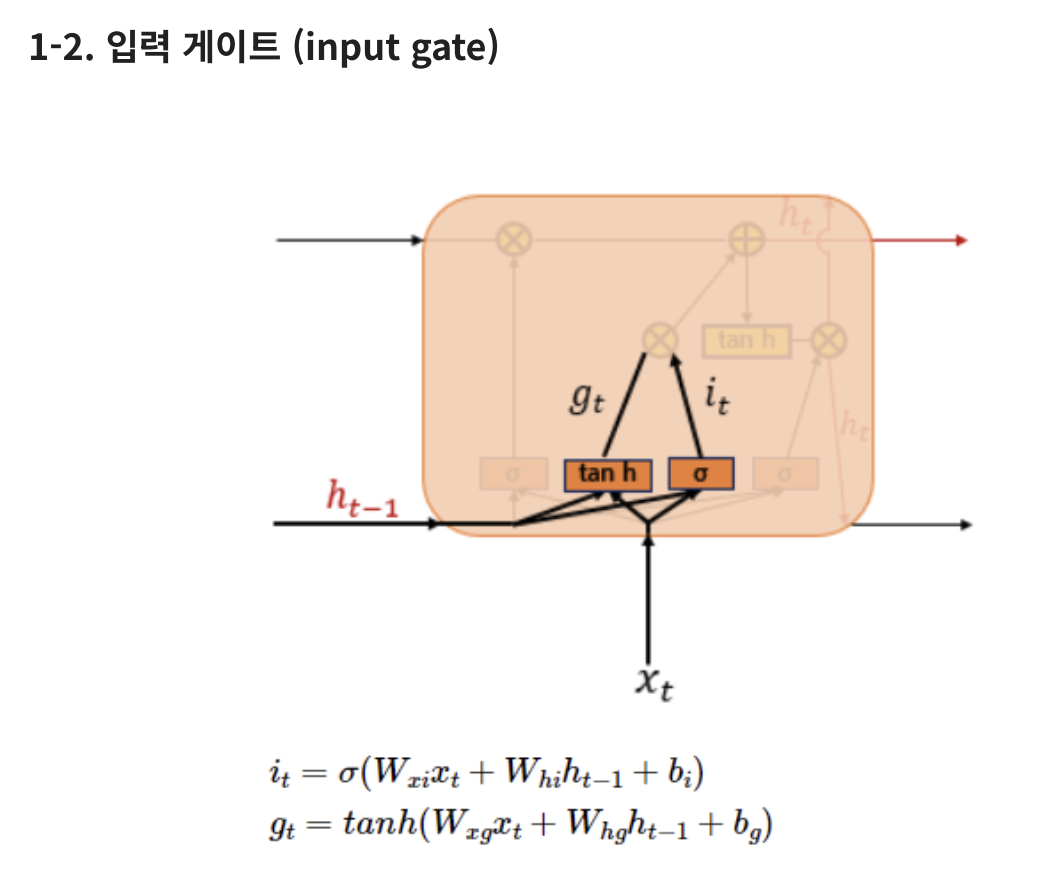
1-2) i(t)를 통해 장기 상태 중 기억되어야할 부분을 제어
i(t) : 0 ~ 1
g(t) : -1 ~ 1


1-3) 장기상태인 C(t)는 C(t-1)의 삭제, 입력 게이트를 거쳐 만들어지는 셀
삭제 게이트 출력값 f(t) = 0이라면 C(t-1)값은 현재 시점 셀 상태값 결정을 위한 영향이 0이 되고
현재 시점의 셀 상태는 오직 입력 케이트 결과가 결정됨
반대로 삭제 게이트 출력값 입력 게이트 출력값이 0이라면 현재 시점 셀 상태값은 오직 이전 시점 셀 상태값인 C(t-1)에 의존함
즉, 삭제 게이트는 이전 시점 입력의 반영을 제어하며, 입력 게이트는 현재 시점 입력의 반영을 제어함
1-4) 출력 게이트는 위 그림의 o(t)로 제어되며 장기 상태의 어느 부분을 읽어 현재 시점의 h(t), y(t)로 출력해야할 지 제어
즉, 현재 시점 입력값 x와 이전 시점의 은닉상태값의 시그모이드 함수 둘을 지닌 값인 o(t)는 현재 시점의 은닉 상태를 결정함
은닉 상태 = 단기 상태
이 값은 출력 게이트 값과 연산되며 값이 걸러지며 다음 시퀀스에 전달되는 은닉 상태가 됨
위 cell state를 추가함으로써 LSTM은 RNN보다 긴 시퀀스 입력을 처리하는데 뛰어남
GRU : Gated Recurrent Units
기존 LSTM의 경우 cell state의 각 gate들을 통해 정보를 선택적으로 활용함
이는 시퀀스가 길더라도 gradient descent를 효과적으로 전파할 수 있음
forget gate : 과거 정보를 얼마나 반영할지
input gate : 현재 정보를 cell state에 얼마나 적용할지 결정
cell state update : f(t)와 C(t)를 통해 이전 시점의 cell 정보를 얼마나 유지할지 결정하여 현재 시점 cell 상태 update
('과거에서 유지할 정보' + '현재에서 유지할 정보')를 가지고 현재 시점의 cell state update
output gate : 현 시점의 cell state를 가지고 출력함과 동시에 다음 hidden state로 넘김
GRU : 기존 LSTM의 구조를 더 간단하게 개선한 모델

'DL 기본개념' 카테고리의 다른 글
| Object Detection 개념 정리 및 학습일지 (0) | 2023.10.27 |
|---|---|
| CV Task (0) | 2023.10.09 |
| GAN, WGAN, WGAN-GP (1) | 2023.09.19 |
| Generative Adversarial Network란? (0) | 2023.08.01 |
| GAN 학습자료 정리 (0) | 2023.07.27 |

