모델 : 다양한 현상을 일정한 표기법으로 표현한 것
추상화 : 일정한 형식에 맞추어 표현
단순화 : 제한된 표기법, 쉬운 이해
명확화 : 정확화
모델링의 3가지 관점
데이터(Data, What) + 프로세스 관점 (Process, How) => 상관관점 (Interaction)
데이터 간 관계 실제 하는 일 / 무엇을 해야하는지 일의 방법에 따른 데이터가 받는 영향
데이터 모델링의 정의
- 정보 시스템 구축을 위한 데이터 관점의 업무 분석 기법
- 현실 세계 데이터를 약속된 표기법에 의해 표현
- DB 구축을 위한 분석/설계하는 과정
데이터 모델링 기능
- 시스템 가시화, 시스템 구조, 행동 명세화, 시스템 구축의 구조화 틀 제공, 시스템 구축 과정 문서화, 세부 사항은 숨기는 다양한 관점 제공, 상세한 수준의 표현 방법 제공
데이터 모델링이 필요한 이유
- 업무 정보를 일정 표기법으로 표기 : 별도의 표기법 => 업무 내용 정확히 분석 가능
- 분석된 모델로 DB 생성 및 개발
- 업무의 흐름 설명
데이터 모델링의 중요성
- Leverage : 적절한 데이터 모델 설계 => 파급효과 적음
- conciseness : 복잡한 정보요구사항을 간결히 표현 (like 설계도면 : 많은 사람이 설계도면만 보고 일사분란하게 이해해야함)
- Data Quality : DB는 기업의 자산, 적절한 모델링을 통해 오랜 시간이 지나도 정확하고 신뢰가능한 데이터를 얻을 수 있음
데이터 모델링의 유의점
- 중복 : 같은 데이터가 여러 장소에 저장되는 것 주의 => 낭비
- 비유연성 : 데이터 정의 시 프로세스와 명확히 분리해야함 => 그래야 유연하다 => 유지 보수 용이
- 비일관성 : 데이터 간 상호연관관계를 명확히 정의해야함 => 분리하면서도 명확한 정의 => 잘 안되어있다면 데이터 일관성이 떨어짐
데이터 모델링 3단계
- 개념적 모델링 : 추상화, 전체에 대한 포괄, 업무 중심적, entity 중심 : ERD
- 논리적 모델링 : 키, 속성, 관계 표현, 재사용성 높음, 정규화 수행
- 물리적 모델링 : 실제 DB에 표현, 물리적 성격으로 개념적보다 구체적이다
프로젝트 생명 주기
- 폭포수
- 정보공학/구조적 방법론
- 나선형
데이터 독립성 <-> 데이터 종속성

각각 독립적으로 구성하여 개별 의미 존재하면서도 서로 결합하여 프로세스로 제공 가능
독립적으로 구성 x
=> 변경 시 데이터 일관성 줄어들 수 있음, 복잡하며 중복이 많음, 요구사항에 대응이 힘듦
- 유지 보수 비용 절감
- 중복된 데이터 감소
- 데이터 복잡도 낮춤
- 요구사항 대응을 높일 수 있음
데이터베이트 3단계 구조
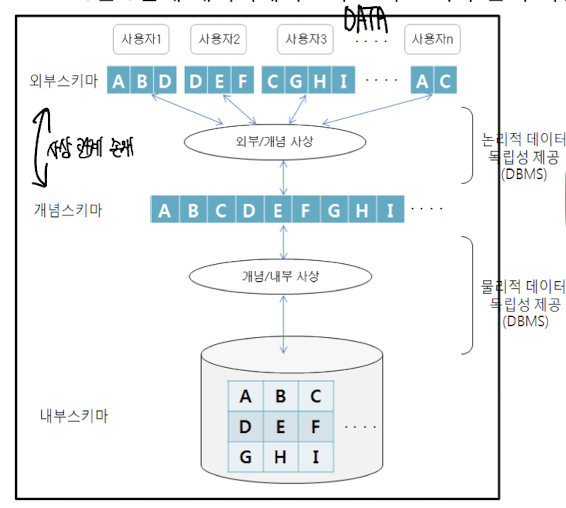
- 외부 단계
- 개념적 단계
- 내부 단계
데이터 독립성 요소
- 외부 스키마
- 개념 스키마
- 내부 스키마
데이터 독립성을 지키기 위해 외부/개념 단계 => 논리적 데이터 독립성
개념 스키마 변형 => 외부 스키마 영향 X
내부/개념 단계 => 물리적 데이터 독립성 존재
내부 스키마 변형 => 개념/외부 스키마 영향 X
*각 스키마 구조는 서로 상호 독립적
*사상 : Mapping
서로 상호독립적 두 개념을 연결시키는 다리
데이터 모델링의 주요 3가지 개념
- 업무가 관여하는 어떤 것 : thing (엔티티타입, 엔티티, 인스턴스)
- 어떤 것이 가지는 성격 : attribute (속성, 속성값)
- 업무가 관여하는 어떤 것 간의 관계 : relationships (관계, 페어링)
데이터 모델 표기법 ERD
엔티티 그리기 => 엔티티 배치 => 엔티티간 관계 설정 => 관계 참여도 설정 => 관계 필수 여부 설정
좋은 데이터 모델 요소
- 모든 데이터는 모델에 정의되어있어야함 : 완전성
- 하나의 DB 내 동일한 fact는 반드시 1번만 : 중복 배제
- ligical data model의 업무 규칙은 명확히 : 업무 규칙
- 데이터는 시스템과 독립적으로 설계 : 데이터 일관성 유지 : 데이터 재사용
- DB 유지보수 및 확장 시 동일한 데이터 1번 정의 => 참조, 활용 용이
- 의사소통, 통합성
엔티티
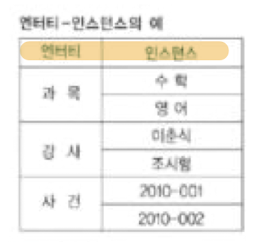
업무에서 반드시 필요한 정보
유일한 식별자에 의해 식별 가능
인스턴스의 집합 : 2개 이상
반드시 속성을 포함해야함
다른 엔티티와의 관계가 존재해야함
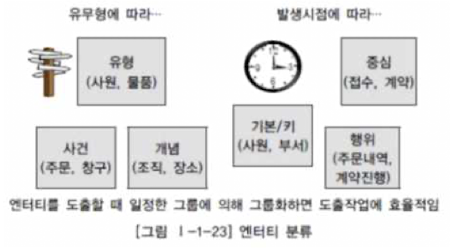
엔티티 분류
- 유형/무형에 따라 : 유형 엔티티(사원, 물품) / 개념 엔티티(조직, 장소) / 사건 엔티티 (주문, 판매)
- 발생 시점에 따라 : 기본 엔티티 (사원, 부서)/ 중심 엔티티(접수, 계약) / 행위 엔티티 (주문내역, 계약 진행)
엔티티 명명 규칙
- 약어
- 현업에서 실제 사용하는 용어
- 단수 명사
- 유일한 이름
- 생성 의미대로 이름 부여
속성
의미상 더 분류되지 않는 최소 단위
엔티티 설명, 인스턴스의 구성요소

엔티티 <-> 속성 <-> 인스턴스의 관계
1개 엔티티 = 2개 이상의 인스턴스 집합
1개 인스턴스 = 2개 이상의 속성 집합
1개 속성 = 오직 1개의 속성값 (최소 단위)
속성 분류

- 속성의 특성에 따라
: 기본 속성 = 기본적 모든 속성 : 업무 분석을 통해 바로 정의한 속성
: 설계 속성 = 사용자에 의해 만들어지거나 정의되는 속성 : 설계를 통해 도출해낸 속성
: 파생 속성 = 다른 속성의 영향을 받아 발생
- 엔티티 구성 방식에 다른 분류
: PK (primary key)
: FK (foreign key)
: 일반
도메인 : 각 속성이 가질 수 있는 값의 범위
{데이터 타입 / 크기 / 제약사항}
속성 명명규칙
- 약어
- 서술식 속성명
- 현업에서 사용하는 용어
- 유일한 이름 부여
관계
엔티티의 인스턴스 사이 연관성 정의
{관계명, 차수(카디널리티), 선택성(옵셔널리티)}로 구성
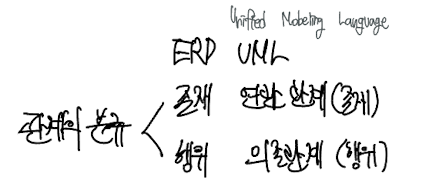
ERD : 구분 없이 단일화된 표기법 사용
UML : 실선과 점선으로 구

관계 해석, 명명 방법
1) Source Entity의 각 인스턴스 확인
2) Target Entity의 관계 참여소 읽음
+ 개수 세서 차수 정함
3) 선택성과 관계명을 읽음
두 엔티티 사이 정의한 관계 체크 사항
- 두 엔티티 사이 연관규칙 존재?
- 두 엔티티 사이 정보 조합 발생? => join?
- 업무 기술서, 장표에 관계 연결을 가능케하는 동사 존재? => 관계 O
- 업무 기술서, 장표에 관계 연결에 대한 규칙 존재? => option
식별자 != key
엔티티를 구분하는 논리적인 이름
각 엔티티에는 반드시 하나의 유일한 식별자 존재
식별자 특징
- 유일성 : 엔티티 내 모든 인스턴스를 유일하게 구분
- 최소성 : 속성 수는 유일성을 만족하는 최소 개수여야함
- 불변성 : 식별자 값은 변하지 X
- 존재성 : NULL
식별자 분류

대표성 여부
- 주식별자 : 엔티티 내 각 어커런스를 구분할 수 있음, 타 엔티티와 참조관계를 연결할 수 있는 식별자
- 보조식별자 : 엔티티 내 각 어커런스를 구분할 순 있지만 대표성을 가지지 못해 참조 관계 연결 X
스스로 생성 여부
- 내부 식별자 : 엔티티 내부에서 스스로 만들어지는 식별자
- 외부 식별자 : 타 엔티티와의 관계를 통해 타 엔티티로부터 받아오는 식별자
속성 수
- 단일 식별자 : 단일 속성으로 구성
- 복합 식별자 : 둘 이상의 속성으로 구성된 식별자
대체 여부
- 본질 식별자 : 업무에 의해 만들어지는 식별자
- 인조 식별자 : 업무적으로 만들어지진 않지만 원조 식별자가 복잡한 구성을 가지고 있기 때문에 인위적으로 만든 식별자

주식별자 도출 기준
- 해당 업무에서 자주 이용되는 속성
- 명칭, 내역처럼 이름으로 기술되는 것은 피함 => 구분자가 존재하지 않을 경우 새로운 식별자 생성
- 복합키의 경우 너무 많은 구성 X
식별자와 비식별자
- 식별자 관계
자식이 부모의 기본키를 상속받아 기본키로 사용
=> 부모로부터 받은 식별자를 자식 엔티티의 주 식별자로 사용
- 반드시 부모 엔티티가 먼저 생성되어야함
- 부모로부터 받은 모든 속성 => 자식 엔티티에 사용 (1 : 1)
- 부모로부터 받은 속성을 포함하여 다른 속성 추가 시 (1 : M)
문제점 : 식별자 관계를 연결한 데이터 모델의 pk 속성 수가 점점 많아짐
주식별자의 속성이 많을 경우 join 관계 시 누락 발생 가능
=> 복잡해지고 오류 가능성 존재
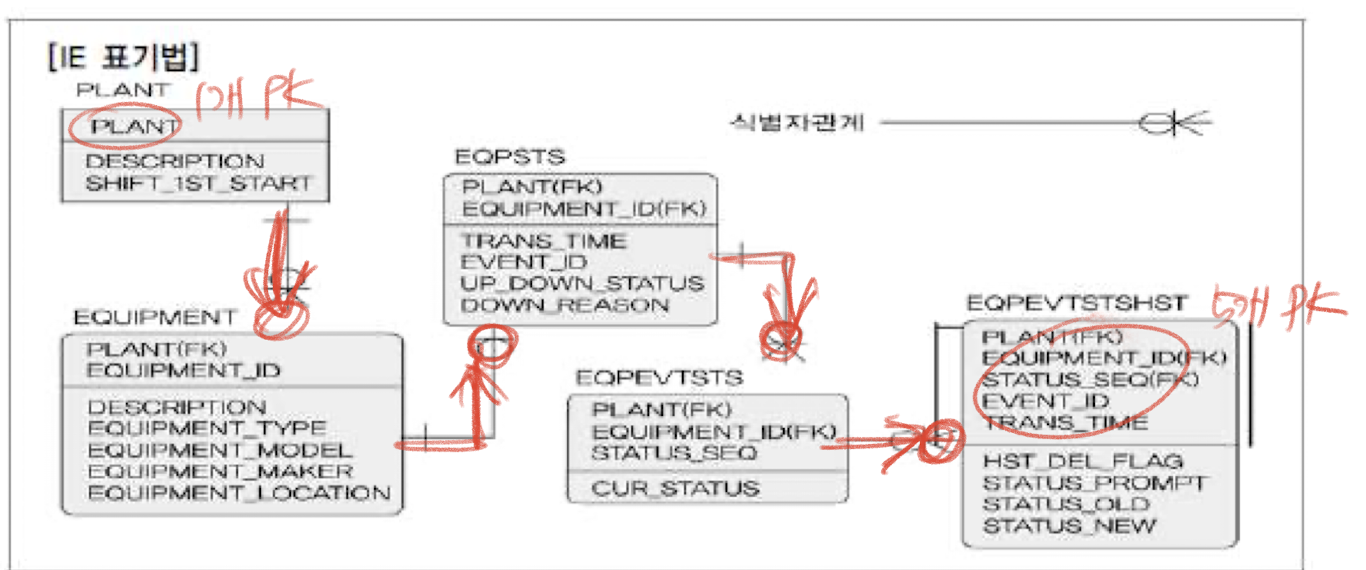
- 비식별자 관계
부모로부터 받은 속성을 기본키로 사용 X, 일반키로 사용하는 경우
- 자식 엔티티만 남겨두고 부모 엔티티 삭제 가능
- 부모 없이 자식 엔티티 생성 가능
문제점 : 부모까지 조인 => sql문 길어짐 : 불필요한 join => 성능 저하
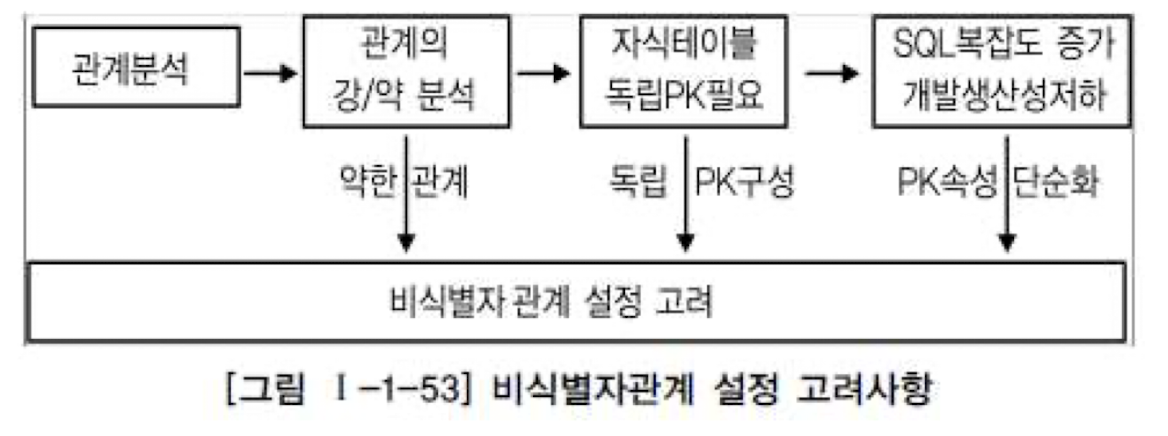
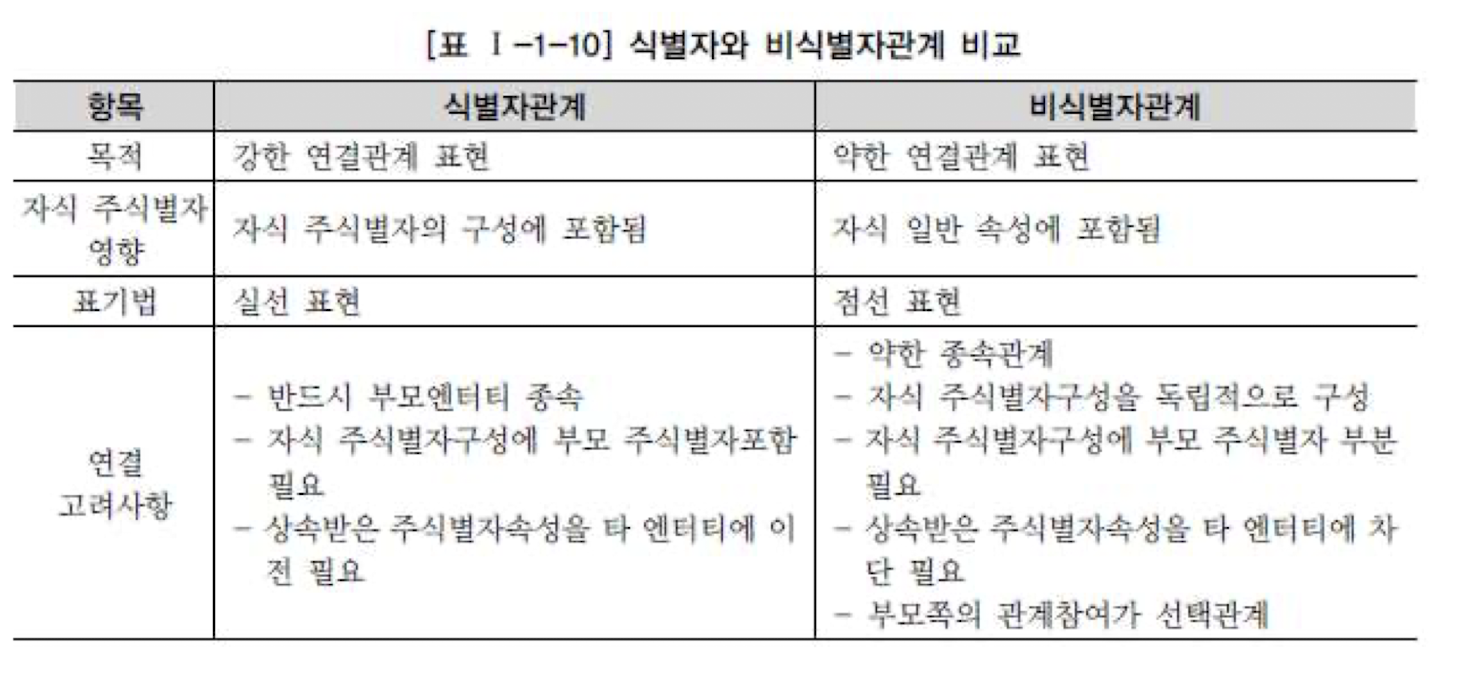
즉 식별자와 비식별자를 적절하게 선택하여 데이터의 균형감을 잘 맞춰야함
'강의 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] (0) | 2023.06.12 |
|---|---|
| [데이터베이스] DB설계 - 정규화 (0) | 2023.06.12 |
| [데이터베이스] E-R 모델 (0) | 2023.05.16 |
| [데이터베이스] DB 설계1 (0) | 2023.05.10 |
| [데이터베이스] 개념 시험 직전에 볼 것들 (0) | 2023.04.24 |