** [실전! 파이토치 딥러닝 프로젝트]를 통해 정리한 글입니다.
딥러닝은 심층 신경망의 수학 개념을 기반으로 대량의 데이터를 사용해 입력과 출력 사이 단순하지 않은 관계를 복잡 비선형 함수 형태로 학습한다. 심층 신경망은 방대한 수학 연산, 선형 대수 방정식, 복잡 비선형 함수, 다양한 최적화 알고리즘을 포함한다.
파이썬 등의 프로그래밍 언어로 심층 신경망을 처음부터 구성하고 훈련하려면 필요한 모든 방정식, 함수, 최적화 스케줄을 모두 작성해야하며 딥러닝 애플리케이션을 만들 때마다 이 세부사항을 모두 구현해야한다.
텐서플로우 같은 딥러닝 라이브러리는 이러한 세부 사항을 추상화하도록 발전했다. 파이토치는 딥러닝 모델을 만드는 데 활용할 수 있는 파이썬 기반의 딥러닝 라이브러리이다.
Pytorch
딥러닝의 기본 개념
파이토치 라이브러리 개괄
파이토치로 딥러닝 모델 훈련 실습
딥러닝 되짚어보기
신경망은 인간의 뇌 구조와 기능에서 본따 만들어졌다.
각 연산 단위를 뉴런이라 하며 뉴런들은 층:layer를 이루어 다른 뉴런들과 연결된다.
층의 개수를 2개 이상으로 구성한 신경망이 deep neural network이며 이러한 모델을 deep learning model이라 부른다.
2024.03.07 - [DL] - Deep Learning : ANN, DNN, RNN, CNN (SLP, MLP)
Deep Learning : ANN, DNN, RNN, CNN (SLP, MLP)
ANN 인공 신경망 : Artificial Neural Network 🚦인간의 뇌 뉴런 : 세포체와 여러개의 수상돌기, 일반적으로 한 개의 축삭돌기로 이루어져있다 수상돌기는 여러 branch에서 들어오는 자극들을 수용 축삭돌
dayofday.tistory.com
-> 딥러닝의 종류를 간단하게 정리해둔 포스팅이다
딥러닝 모델은 입력 데이터와 출력 사이의 복잡한 관계를 학습하는 능력으로 기존의 머신 러닝 모델을 능가하는 것을 입증하였다.
현재 전세계는 방대한 양의 데이터들이 발생하고 있다.
따라서 방대한 양의 데이터를 다루기에 적합한 딥러닝이 떠오르게 되었다.
더불어 전통적 머신러닝 기반의 접근법인 feature engineering이 훈련된 모델의 전반적 성능에 결정적 역할을 하였다면 딥러닝 모델에서는 특징을 공들여 수동으로 만들 필요 없이 대용량 데이터를 잘 다루면서 머신러닝 모델을 능가할 수 있다.
딥러닝의 성능이 반드시 데이터셋 크기에 따라 구분되는 것은 아니지만 크기가 커질 수록 심층 신경망이 딥러닝이 아닌 모델보다 성능이 우수해진다.
이러한 심층 신경망은 구성하는 계층의 유형과 조합에 따라 아키텍처를 몇 가지로 구분하게 된다.
Fully-connected layer = Linear layer

완전 연결 계층에서는 앞서 나온 계층의 모든 뉴런이 뒤의 계층의 모든 뉴런과 연결된다.
완전 연결 계층은 대부분의 딥러닝 분류 모델의 기초 단위이다.
Convolution layer

합성곱 커널이 input 위에서 이동하는 합성곱 계층 형태이다.
합성곱 계층은 computer vision 문제를 위한 가장 효과적인 모델인 convolution neural network:CNN의 기초 단위이다.
Recurrent layer

순환계층이다.
fully connected layer와 비슷하게 생겼지만 순환되는 연결이 핵심 차이점이다.
순환함으로써 기억하는 능력을 보여주며 현재 입력과 함께 과거 입력을 기억해야하는 sequential data를 다룰 때 편리하다.
DeConv layer
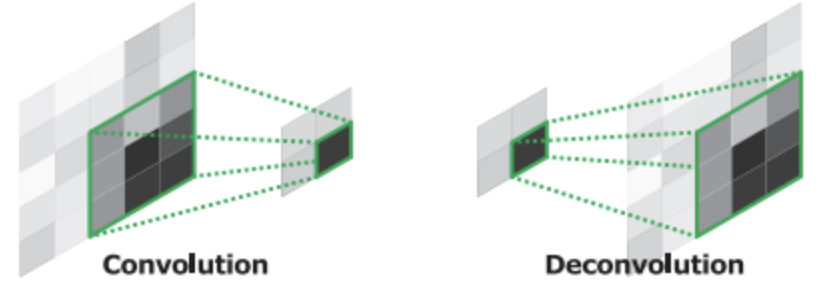
합성곱 계층과 정반대이다.
입력 데이터를 공간적으로 확장 적용함
-> 이미지 생성 또는 재구성을 목표로하는 모델에서 핵심적인 계층
Pooling layer

풀링 계층 중 가장 널리 쓰이는 max-pooling
입력을 2*2 크기 단위로 나눈 후 각 부분에서 가장 높은 숫자를 뽑는다.
- mean-pooling
- min-pooling
Drop-out layer

드롭아웃 계층을 통해 일부 뉴런의 스위치가 일시적으로 꺼진다.
일부 뉴런을 네트워크에서 연결을 끊어냄으로써 훈련 데이터셋에만 과도하게 학습되는 것을 막는다.
일반화 학습
model regularization에 도움이 된다.
https://www.asimovinstitute.org/neural-network-zoo/
The Neural Network Zoo - The Asimov Institute
With new neural network architectures popping up every now and then, it’s hard to keep track of them all. Knowing all the abbreviations being thrown around (DCIGN, BiLSTM, DCGAN, anyone?) can be a bit overwhelming at first. So I decided to compose a che
www.asimovinstitute.org
-> 다양한 신경망 아키텍처들을 확인할 수 있다.
활성화 함수 : activation function
우리는 활성화 함수를 통해 신경망에 비선형성을 추가한다.
비선형성이 없다면 아무리 많은 계층을 추가하더라도 단순 선형 문제로 회귀하게 된다. -> deep의 의미가 사라짐
복잡한 문제에 대한 적절한 최적화 기법을 적용하기 위해서는 비선형성이 필요하다.
- sigmoid function

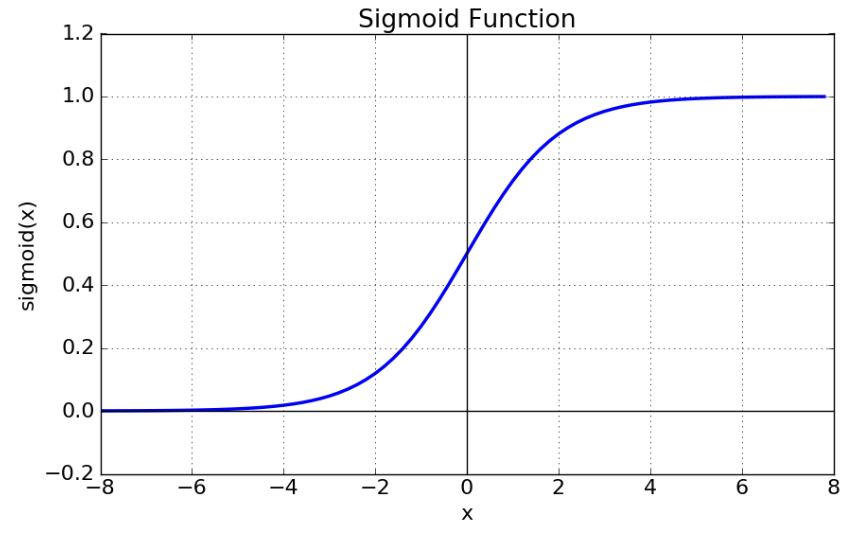
x의 숫자 값을 입력으로 받아 (0,1) 사이 값을 y로 출력한다.
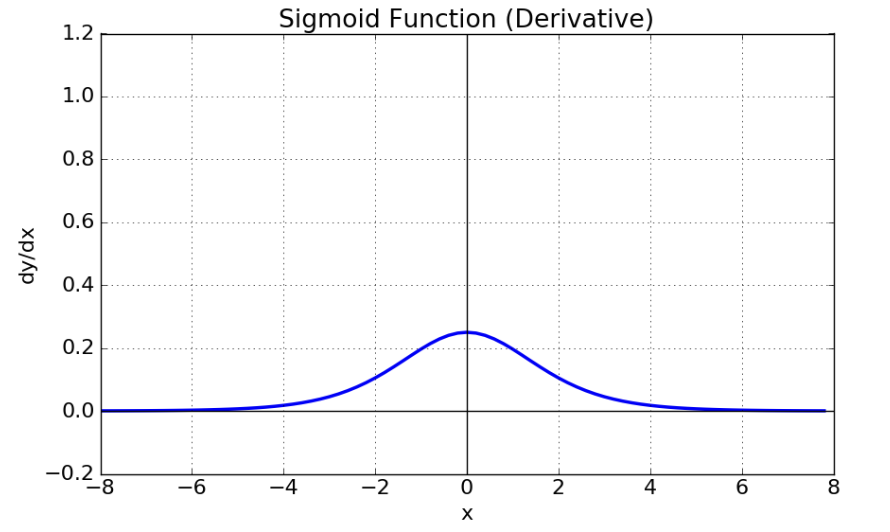
sigmoid의 문제점
- input 값이 커질 수록 미분값이 0에 수렴한다
기울기 소실 : gradient vanishing 문제 발생
미분값이 0에 수렴하게 되면서 역전파 과정에서 적절한 학습이 이루어지지 않게 된다
- zero-connect 하지 않아 역전파 과정에서 zig-zag로 수렴하게된다
즉, 학습이 안정적이지 않다.
- TanH : 쌍곡선 탄젠트 (Hyperbolic Tangent)


시그모이드와 다르게 tanh 함수는 y값 출력이 (-1,1)이다.
따라서 출력으로 양수와 음수가 모두 필요할 경우 유용하다.
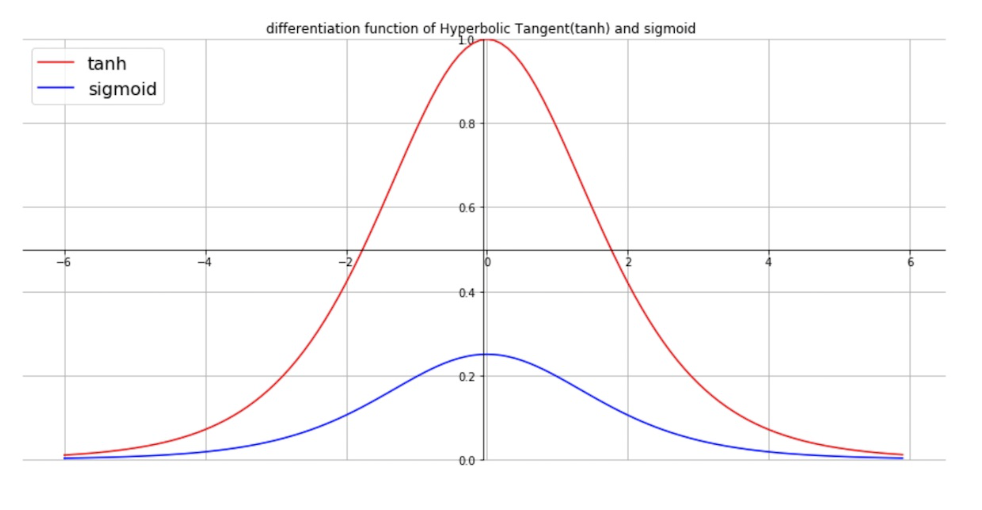
sigmoid에 비해 미분값이 안정적으로 커짐
더불어 zero connect
하지만 여전히 값이 커지게 되었을 때 기울기가 소실되어 vanishing gradient 문제 존재
- Rectified linear units : ReLU

sigmoid와 tanh 함수에 비해 입력값이 0보다 큰 경우 항상 출력값이 증가한다 -> vanishing 문제 해결
하지만 여전히 입력이 음수이면 출력과 경사 모두 0이다
- Leaky ReLU
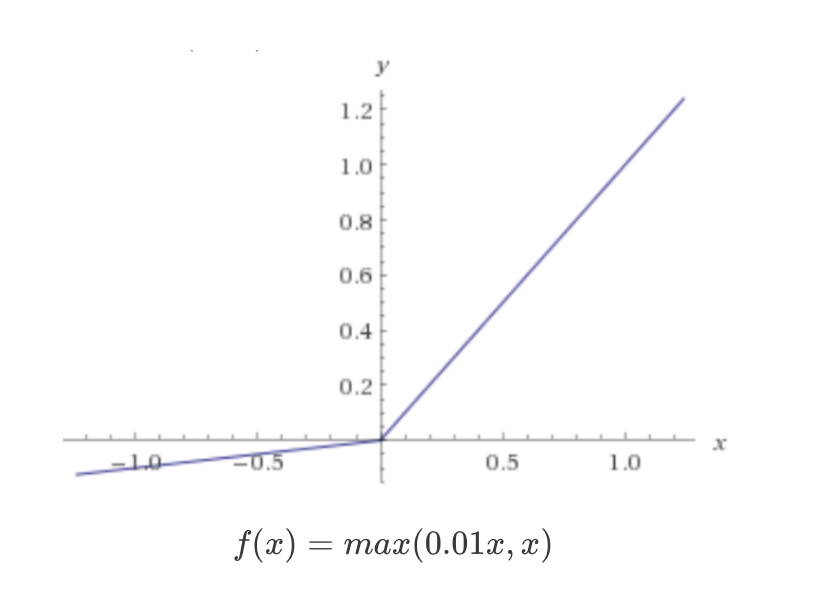
ReLU의 문제점인 입력이 음수일 때, 출력과 경사가 0이 되는 문제를 아주 작은 값을 넣어 해결함
음수 입력을 처리해야할 필요가 있을 경우 유리
대표적으로 이러한 활성화 함수들이 있으며 이 부분은 딥러닝에서 활발하게 발전하는 분야로 수많은 활성화 함수들이 언급한 활성화 함수를 미세하게 수정한 것들이다.
신경망을 훈련시키려면 최적화 스케줄을 선택해야한다
매개변수 기반 머신러닝들과 동일하게 딥러닝 모델 또한 매개변수를 조정함으로써 훈련된다
매개변수는 backpropagation 과정을 통해 조정되며 신경망의 최종:output 계층은 손실을 계산한다
이 손실은 신경망의 최종 계층의 출력과 그에 대응하는 정답을 취하는 손실함수에 의해 계산된다
이렇게 손실함수를 통한 output과 정답 label 간의 오차 계산을 통해 이전계층으로 손실이 전달되게 되는데 이때 gradient descent와 연쇄 함수 미분이 적용된다
각 층의 매개변수나 가중치는 손실을 최소화하도록 적절히 수정되며 수정 범위는 0~1 사이 값을 갖는 계수인 학습률에 의해 결정된다.
신경망의 가중치를 업데이트하는 이러한 모든 절차를 최적화 스케줄이라 한다.
'ETC..' 카테고리의 다른 글
| 윈도우 10 RTX 4090 쿠다 환경설정 (2) | 2024.09.21 |
|---|---|
| 가상 환경 설정 및 DL 학습 환경 설정 (0) | 2024.07.12 |
| [ISSA 알고리즘 분석] (1) | 2023.11.03 |
| 의료영상 데이터 전처리 (0) | 2023.10.05 |
| [구강암 배경지식] (0) | 2023.09.26 |

