이미지에 대한 캡션 평가 및 순위를 매기는 new framework
: ECO(Ensembled Clip score and cOnsensus score)
주어진 이미지에 대해 후보 캡션들 중 가장 정확하고 포괄적인 캡션을 식별하는 것을 목표로 하는 대회
→ 이미지를 정확하고 철저하게 설명할 수 있는 캡션 선택
NICE 데이터셋
20,000개 이미지
각 이미지에 대한 60개 후보 캡션
→ 제로샷 평가 데이터셋
평가스코어
CIDEr : 주어진 캡션이 여러 참조 캡션과 얼마나 일치하는가
캡션의 단어 조합의 가중치를 계산해 중요 단어가 얼마나 잘 표현되었는지 측정
SPICE : 캡션의 의미론적 구조 분석, 평가
단순한 단어 일치보다 객체, 관계, 속성 등 이미지의 의미적 내용이 얼마나 잘 묘사되었는가
METEOR : 번역 품질 혹 캡션 평가에 사용
단어 정렬, 동의어 일치, 형태소 분석을 통해 단순 일치보다 더 높은 평가 정확도 제공
ROGUE-L : 텍스트 요약과 같은 NLP 작업에 사용되는 지표
두 텍스트 간 최장 공동부분 시퀀스를 측정해 캡션의 연속성, 일관성을 평가함
BLEU : 기계 번역 평가를 위해 개발된 지표
n-그램 매칭을 기반으로 생성된 캡션이 참조 캡션과 얼마나 유사한지 평가
- n-그램 가중치
- 텍스트에서 연속된 n개의 단어 묶음
1-그램(unigram): "나는", "책을", "읽는다"
2-그램(bigram): "나는 책을", "책을 읽는다"
3-그램(trigram): "나는 책을 읽는다"
이미지의 설명 품질을 기반으로 캡션을 재정렬하기위해서는 과연 무엇이 “정확하고 철저한” 캡션을 구성하는지를 명확히 하는 것이 중요
- 이상적인 캡션은 해당 이미지와 높은 의미적 일치를 가져야한다
- 이상적인 캡션은 높은 필수성을 가져야한다
높은 의미적 일치 : 캡션이 이미지의 맥락을 정확히 반영해야하며 이미지에 존재하지 않는 내용을 포함해서는 안된다
높은 필수성 : 지나치게 과장된 언어를 피하고 필요한 표현만 사용해야함, 따라서 각 표현이 이미지의 정확한 묘사를 위해 얼마나 필수적인지 확인
캡션은 위 기준을 모두 충족해야 이상적 캡션임
→ 의미적 일치도가 높더라도 비필수적 요소를 포함할 수 있음
→ 필수요소에만 집중하면 이미지의 충분한 표현을 놓칠 수 있음
평가 과정
1️⃣ 이미지와 캡션 간의 일치도 평가를 위해 저자들은 다양한 사전학습된 CLIP 모델 및 BLIP-2 모델 사용
2️⃣ 이미지와 텍스트 특징 간의 코사인 유사도를 계산
3️⃣ 이 결과들을 결합하여 강건한 Ensembled CLIP 점수 생성
4️⃣ ensembled clip & consensus 점수를 결합하여 최종 점수 계산
5️⃣ 상위 두 캡션의 차이가 미미할 경우, 단어수가 적은 캡션 최종 선택
→ 제안된 ECO 프레임워크는 이해하기 쉽고 파인튜닝이 필요하지 않음
Proposed Method
이미지와 캡션 간의 의미적 일치도 및 캡션의 필수성을 모두 고려하여 이상적 캡션 선택
Ensembled CLIP score
→ 이미지와 캡션 간의 의미적 일치 평가
사전학습된 clip 모델을 사용해 이미지 임베딩(EI)와 캡션 임베딩(EC) 간의 코사인 유사도 비교
But, 사전학습된 clip 모델의 학습 데이터가 제공된 제로샷 캡션 재정렬 데이터셋과 다를 수 있어
단일 clip 점수의 정확도가 신뢰할 만하지 않을 수 있음
⇒ 제로샷 작업에서 성능이 검증된 다양한 모델의 clip 점수를 앙상블로 사용하면 단일 clip 점수보다 더 강건한 의미적 일치도 제공

일반적 clip 점수는 Ei와 Ec간의 코사인 유사도를 사용해 의미적 일치를 측정하며 음수 값은 0으로 대체하지만
ECO의 경우 관련성이 낮은 이미지-캡션 쌍에 대해 더 정밀한 점수 분포를 얻기 위해 음수 값 그대로 유지
Consensus score
→ 후보 캡션들 간의 상호 비교를 통한 필수성 측정
필수성 : 캡션이 필수 표현으로 구성된 정도
다양한 모델이 서로 다른 캡션을 생성할 때, 가장 자주 나타나는 표현이 이미지를 설명하는데 필수적인 것으로 간주
Consensus score는 CIDEr 점수에서 파생된 지표
후보 및 참조 캡션 전체의 N-그램에 대해 TF-IDF 가중치를 계산
이후 후보 캡션과 각 참조 캡션의 TF-IDF 가중치 벡터 간 코사인 유사도 계산
캡션 내 표현 필수성 평가를 위해 평가 대상 캡션을 제외한 모든 후보 캡션을 참조 캡션으로 사용해 각 캡션의 consensus 점수 계산
Caption Filtering
But, consensus 점수의 정확도는 참조 캡션들의 품질에 따라 달라짐
→ 참조 캡션이 고품질일수록 더 정확하게 캡션의 중요한 부분을 평가할 수 있음
이를 위해 고품질 캡션만 포함된 참조 캡션 풀을 만들기 위해 두 가지 필터링을 사용하여 점수를 향상시킴
1️⃣ Bad Format Filter
일반적인 캡션은 하나의 문장이나 구로 구성이 되어있으며 이미지에 대한 충분한 정보를 포함함. 고품질의 관련성 높은 캡션을 보장하기 위해 2개 이상의 마침표 OR 3개 이상의 쉼표를 포함하거나 5 단어 이하로 구성된 캡션은 필터링을 통해 제거함
→ 규칙 기반 알고리즘을 사용하여 평가 대상 캡션이 일반적인 기준을 보장할 수 있도록 함
2️⃣ ITM Filter
후보 캡션 중 이미지 내용과 관련 없는 캡션을 걸러내기 위해 ITM 필터 사용
이미지와 텍스트의 일치성을 평가하는 BLIP-2의 ITM Loss를 사용해 이미지와 캡션 쌍을 positive와 negative로 분류
각 이미지와 연관된 모든 캡션의 ITM 손실을 계산하여 ITM 값이 높은 상위 50% 캡션을 선택함
이 캡션들은 consensus 점수 평가에 사용될 캡션 풀에 포함되며 이로써 이미지 내용과 더 관련성이 높은 캡션들이 평가에 반영되도록 함
Score Combination Setting
점수 결합 가중치 설정 시, consensus 점수와 ensembled clip 점수를 어떻게 활용하느냐에 따라 결과가 크게 달라짐
- Consensus 점수만 사용해 선택한 캡션과 Consensus 점수와 Ensembled CLIP 점수를 동일하게 사용해 선택한 캡션을 비교했을 때, 20,000개의 캡션 중 5,396개에서 차이
- Ensembled CLIP 점수만 사용한 경우와 Consensus 점수를 결합한 경우에는 18,217개의 캡션에서 차이가 발생
두 점수를 정규화하여 분포를 시각화해본 결과 consensus의 최대값이 clip 점수의 최대값보다 약 3배 더 큼
⇒ consensus 점수의 영향력이 보다 큼을 확인할 수 있음
양 점수를 균형있게 반영하기 위해 consensus 점수의 가중치를 ensembled clip 점수의 가중치보다 더 크게 설정함 1:3.52
Consensus Scoring’s Effectiveness in Identifying Essentialness
ITM 필터와 Bad form 필터의 효과를 평가하기 위해, 필터링된 캡션과 필터링되지 않은 캡션의 consensus score 비교

Effects of Caption Filtering
ITM 필터와 Bad form 필터링되지 않은 경우의 평가 결과 비교
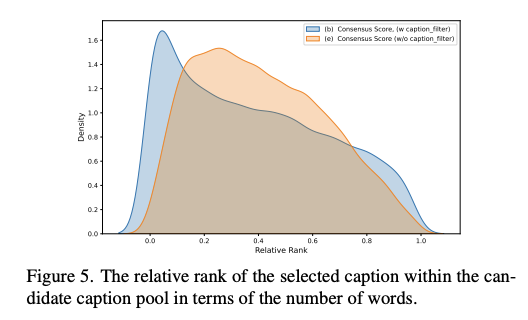
→ 선택된 캡션의 상대적 순위를 단어 수 측면에서 시각화함
→ 필터링 후 선택된 캡션이 눈에 띄게 더 짧음을 확인함
Effects of the Short Caption Selection

짧은 캡션을 선택하는 것이 더 효과적임
Conclusion
이미지-캡션의 의미적 일치와 캡션의 필수성을 모두 통합한 제로샷 캡션 재정렬 프레임워크인 ECO를 제안
별도의 학습 없이도 여러 후보 캡션 중 가장 이상적인 캡션을 선택할 수 있음
'Paper Review > Multimodal Learning' 카테고리의 다른 글
| [Paper Review] CLIP : contrastive language image pre-training (0) | 2024.02.21 |
|---|---|
| XAI for In-hospital Mortality Prediction via Multimodal ICU Data (1) | 2024.02.05 |
| Multimodal foundation model 기본 개념 (0) | 2024.02.04 |


