개요 : 머신러닝
기존 컴퓨터 학습과 다르게 머신러닝은 input과 output으로 중간 과정의 함수를 찾아낸다
데이터 기반 통계적 신뢰도 강화, 예측 오류 최소화를 위한 다양한 수학적 기법을 적용하여 숨겨진 패턴을 인지, 신뢰도 있는 예측 결과 도출
학습 데이터의 예측 오류를 최소화하기 위해 최적화 알고리즘 사용
영상 인식, 음성 인식, 자연어 처리, 데이터 마이닝 등 머신러닝 적용하며 급속한 발전
1. 머신러닝 중 딥러닝 : deep learning
인간 뇌의 학습과 기억의 메커니즘 모방 //주어진 입력 데이터로 답을 유추할 수 있는 최적의 함수를 찾는 것
how??
F(X) = w0 + w1*x1 + w2*x2 + w3*x3 + .......+wn*xn
최적의 가중치 w를 학습을 통해 찾아냄 => 즉, 딥러닝이 학습하는 것은 가중치 W
딥러닝을 위한 사전 지식
-퍼셉트론
perceptron
가장 단순한 형태의 신경망
hidden layer 없이 single layer로 구성됨 //입력 피처들과 가중치, activation, 출력 값으로 구성
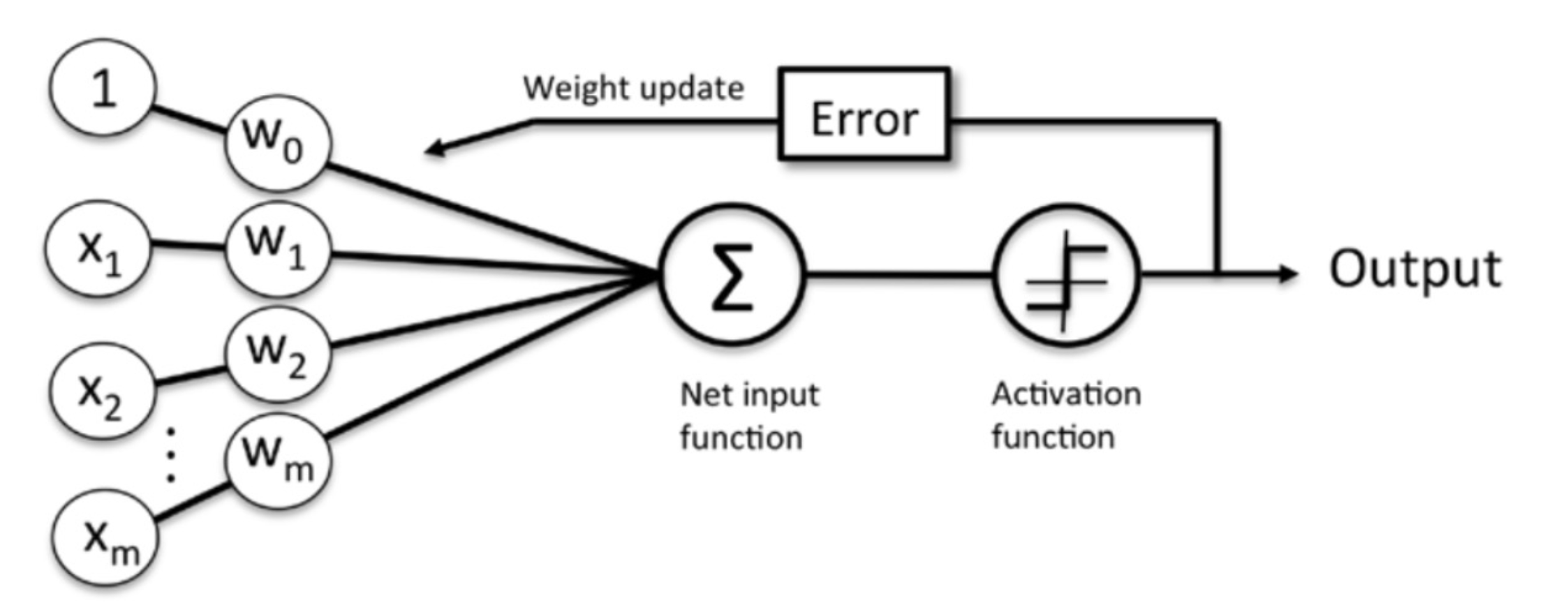
기본 가중합 도출
도출된 weighted sum에 activation 함수 적용(sigmoid/ReLu ,,)
적용하여 최종 도출된 output하고 실제값 비교해서 weight update해가며 실제값과 출력 차이 줄이는 방향으로 학습 진행
그렇다면 어떻게 차이를 줄이는가?
간단한 단순 선형 회귀라고 가정하고 알아보자
비용 함수(cost function / loss function) 값을 통해 오차 정도를 알아낸다
: 단순 선형 회귀의 경우 일반적으로 RSS/MSE를 통해 오류 합을 구함
비용함수를 통해 반환되는 오류값이 지속하여 감소하는 방향으로 학습 진행하여 차이를 줄여나간다.
-경하 하강법
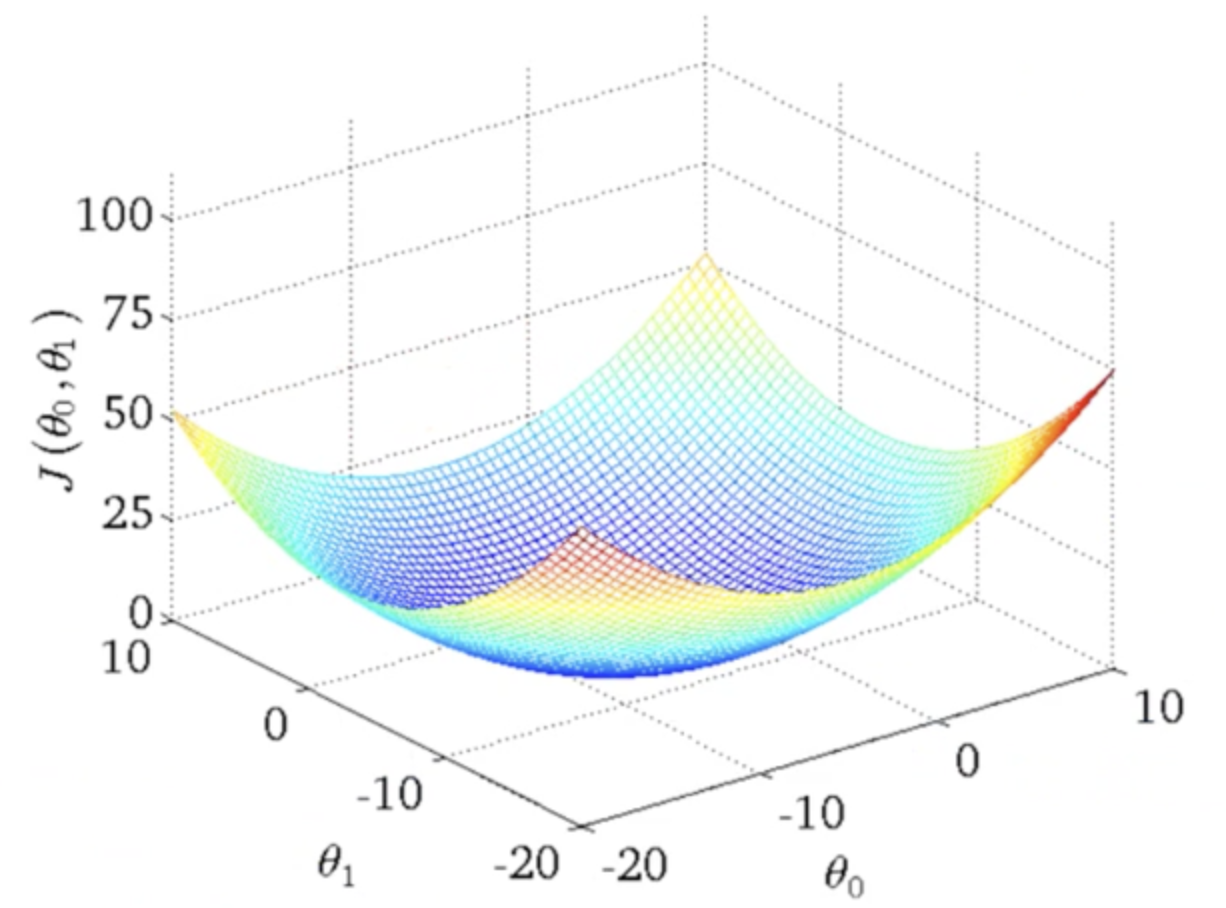
Gradient Descent : 비용 최소화 방법
"점진적인 하강"이라는 의미에 맞게 점진적으로 반복적인 계산을 통해 W 파라미터 값을 업데이트하여 오류값이 최소가 되는 W 파라미터 도출
아까 위에서 차이를 수치적으로 보여주는 함수 언급함 => loss function
그렇다면 이제 이 수치를 줄이는 방향으로 학습한다는 건 알겠는데 그래서 어떻게 한다는거냐?
이때 gradient descent 적용하는거지
키워드는 미분이라고 할 수 있겠다.
미분 = 증가와 감소의 방향성을 나타낼 수 있음
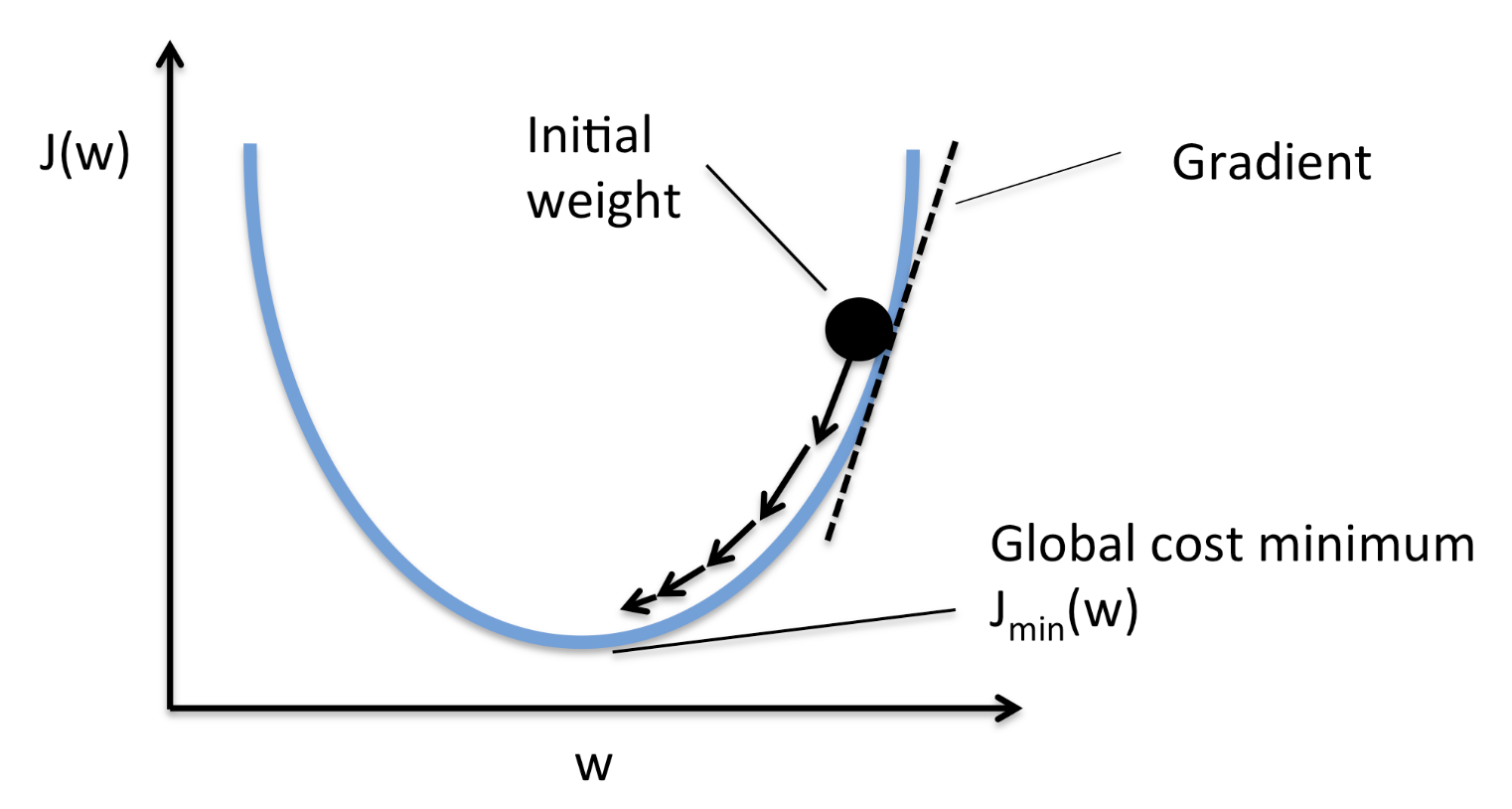
비용함수에 미분을 적용하여 미분 값이 계속 감소하는 방향으로 w update
더이상 미분 값이 감소하지 않는 지점 = loss function의 minimum
더 구체적으로 알아보자면 우리가 여기서 집중해야할 변수는 x가 아닌 w임
w값을 각각 편미분 진행하여 각 편미분 값을 update하면서 갱신하게됨
이때 update 시 그냥 감소시키지 않고 일정 학습 계수인 learning rate을 곱하여 감소시킴
+ learning rate이 너무 작으면 수렴에 오래 걸리고 너무 크면 발산하거나 minimum을 찾지를 못함
정해진 iteration 수만큼 손실함수의 편미분을 구하고 weight, bias update 수행
이때 gradient도 다양한 종류가 존재
| gradient descent:GD | stocastic gradient descent:SGD | mini-batch GD |
| 전체 학습 데이터 기반 GD 계산 | 전체 학습 데이터 중 한건만 임의로 선택해 적용 | 전체 학습 데이터 중 특정(batch) 크기만큼 임의로 선택해 적용 |
| computing 자원이 많이 필요:메모리 부족 | 대부분의 딥러닝 framework가 선택 |
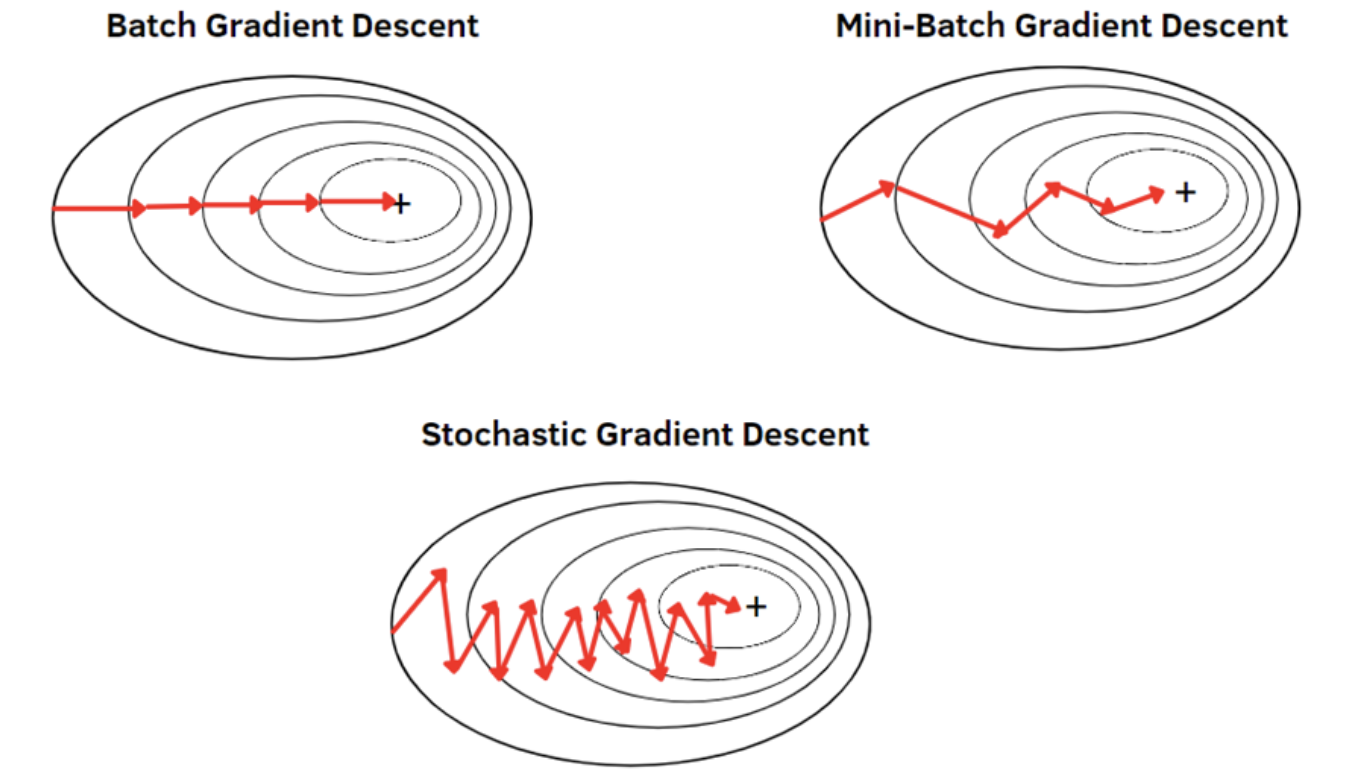
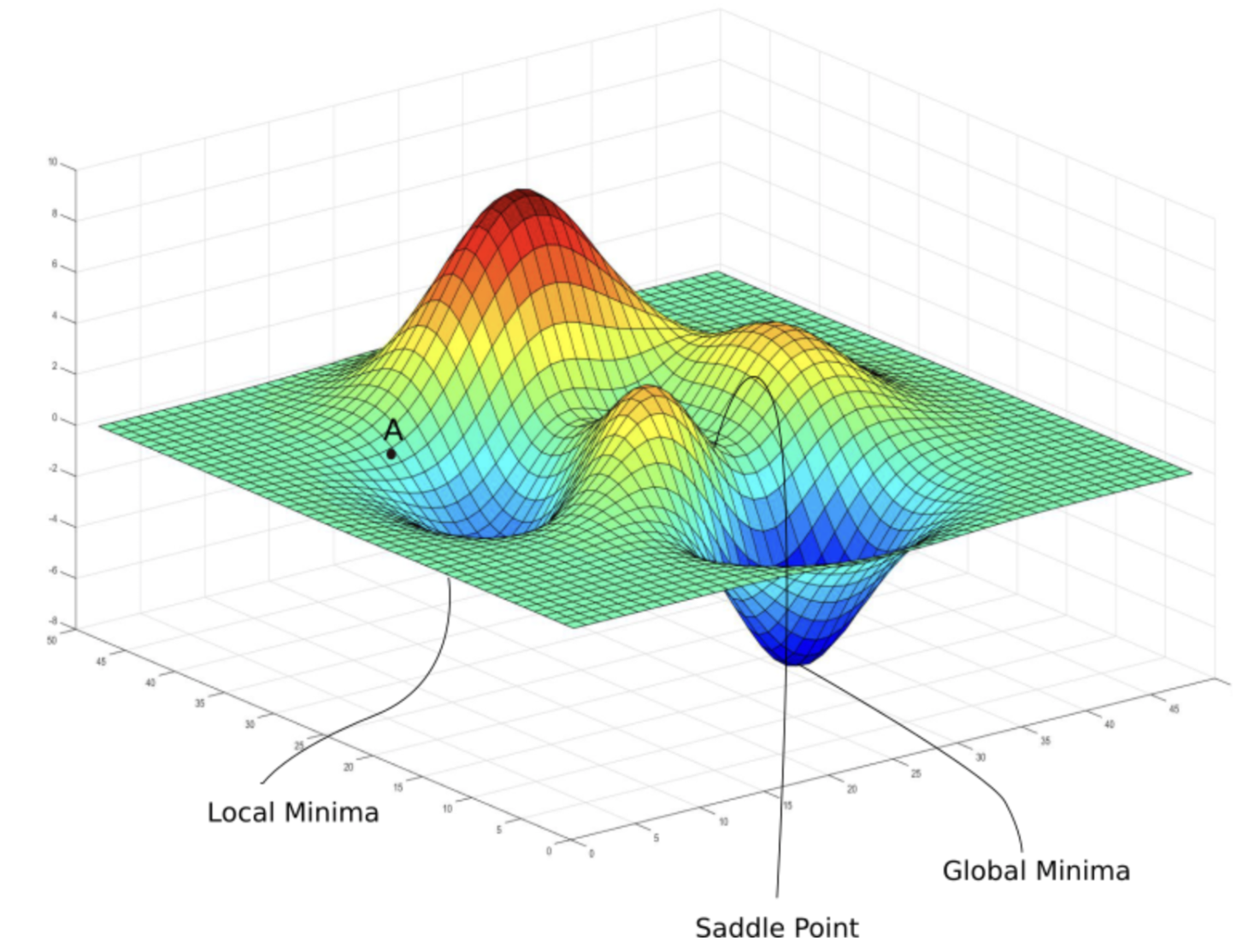
+학습 시 주의할 점 하나 더,, 전역 최소점 즉, global minimum을 찾아야하는데 국소 최소점 즉, local minimum을 찾음
-Back Propagation
위에서 gradient descent에 대해 배움
이때 위 예시는 단순한 함수임,, 그러나 앞으로 우리가 cnn 학습에 적용할 것은 굉장히 복잡한 함수들,,
이런 복잡한 함수에 단순히 편미분한다,,? 말이 쉽지,,
복잡한 함수? 무슨 말이냐
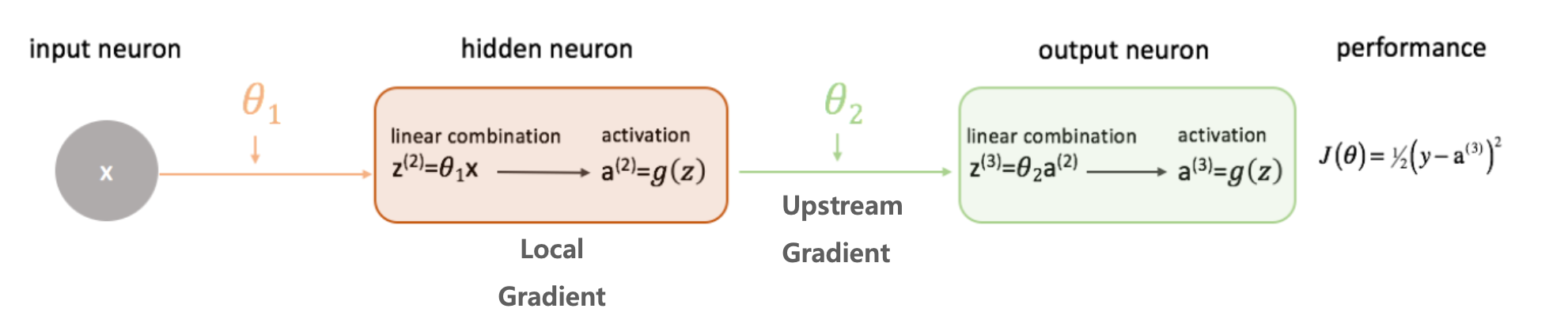
위에서 우리가 살펴본 퍼셉트론은 은닉층이 없었지,, 근데 보다 복잡한 문제를 해결하려면 은닉픙이 포함된 다중 퍼셉트론으로 심층 신경망을 구성한다 이거지..
그래서 나온것이 back propagation
1. feed forward 수행
2. back propagation 수행하며 weight update
3. 1,2 iteration만큼 반복 수행
그래서 back propagation이 뭐냐?
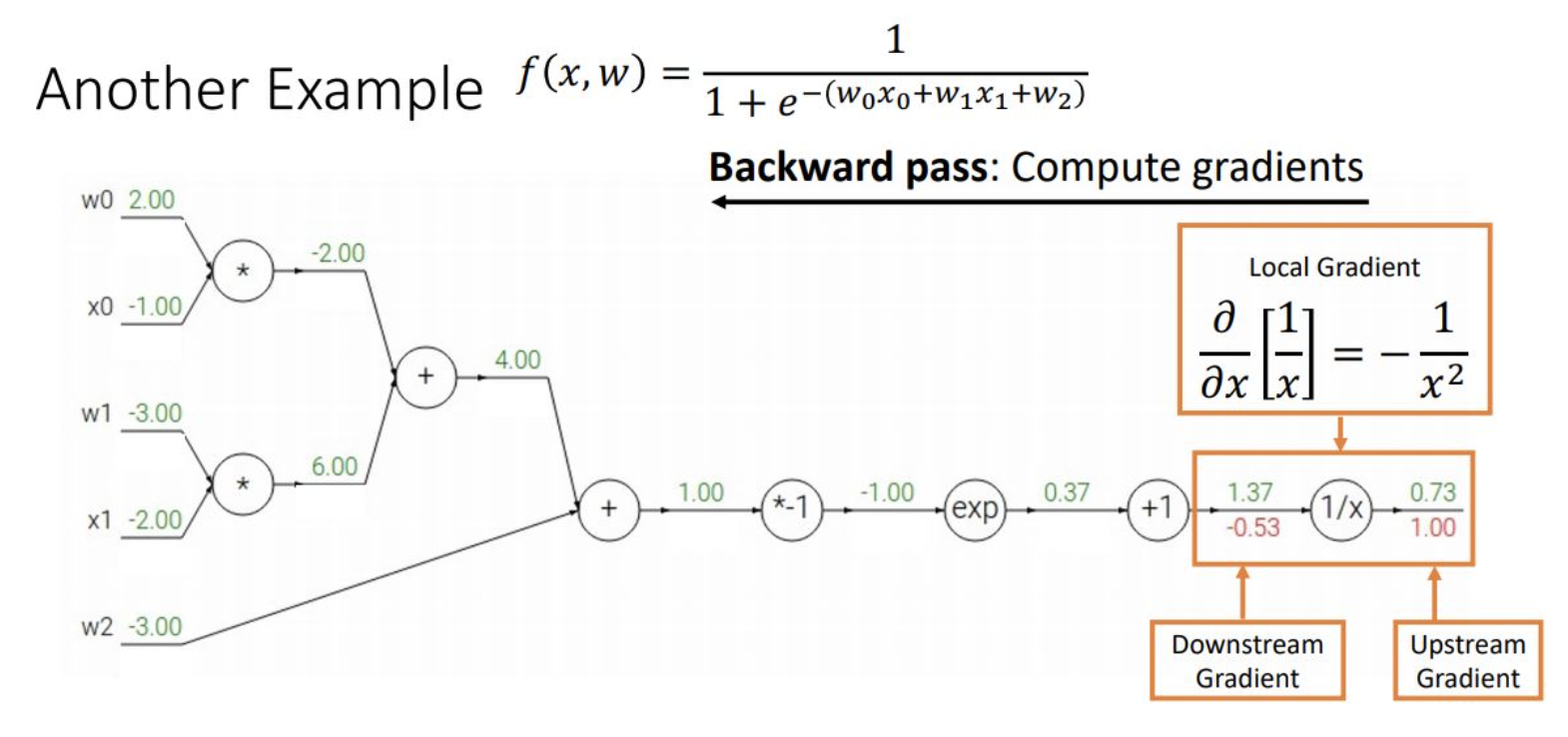
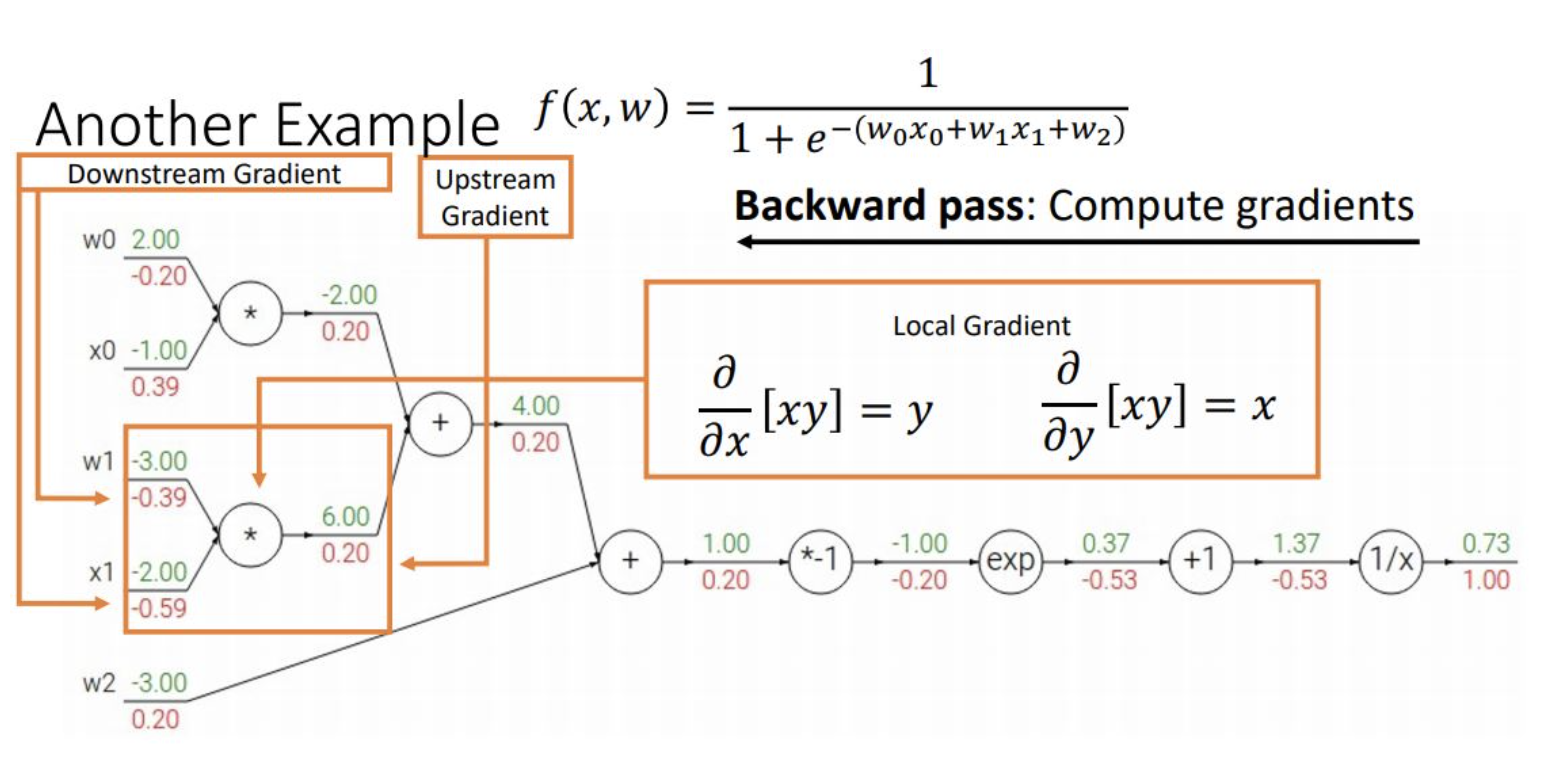
출력층부터 역순으로 gradient 전달하며 전체 layer의 가중치를 update함
쉽게 말해 출력층부터 합성 함수 미분으로 오렌지 껍질가듯 하나씩 진행하며 고차원 식을 보다 간편하게 미분할 수 있음
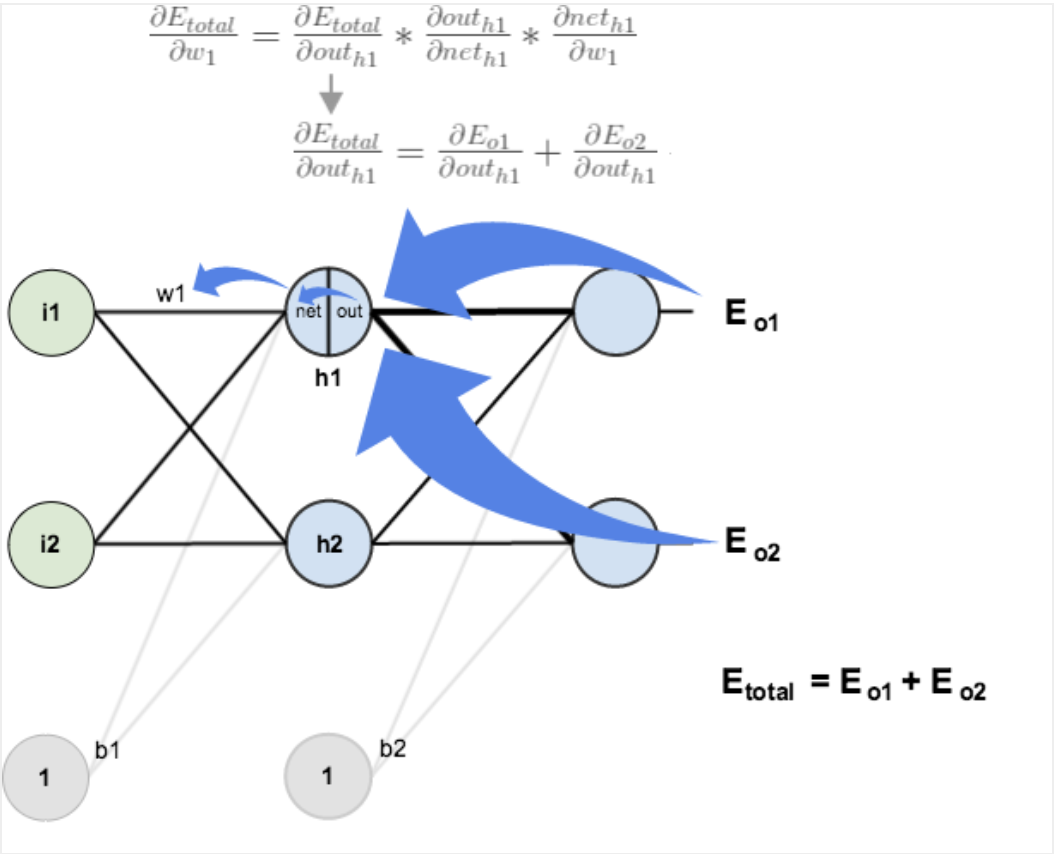
심층 신경망은 합성 함수의 연쇄 결합이므로 합성함수 미분으로 역순 계산이 용이함
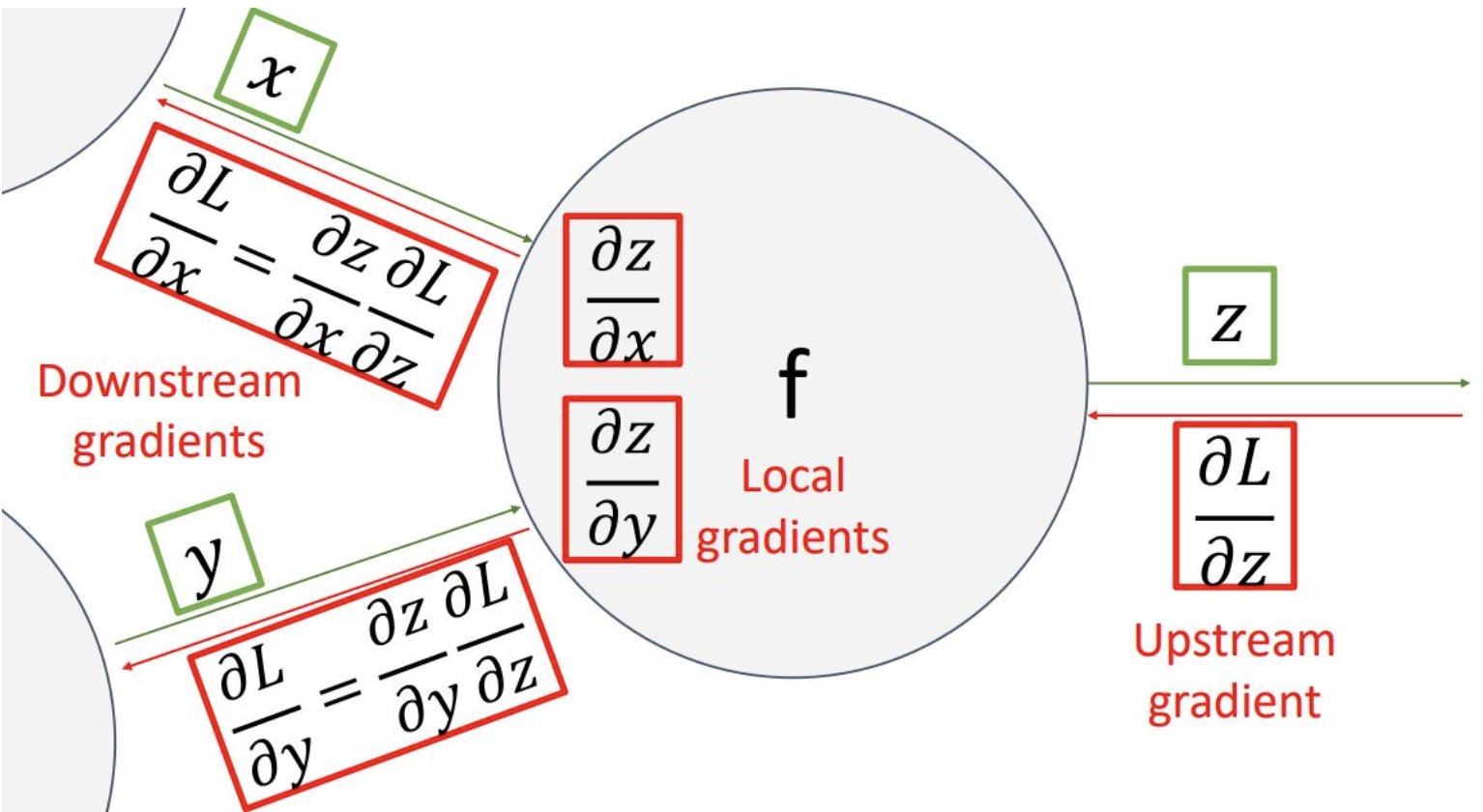
더불어 현 노드의 gradient는 이전 upstream gradient와 local gradient를 곱해서 간단하게 구할 수 있음
'CNN 개념정리' 카테고리의 다른 글
| Activation Function, Loss Function (0) | 2023.08.28 |
|---|---|
| [섹션 9] (0) | 2023.07.15 |
| [섹션 7] (0) | 2023.07.11 |
| CNN 전체 학습과정 (0) | 2023.07.10 |
| 섹션 5 (0) | 2023.07.05 |

