1) activation function
활성화 함수 : 네트워크에 비선형성을 부여함
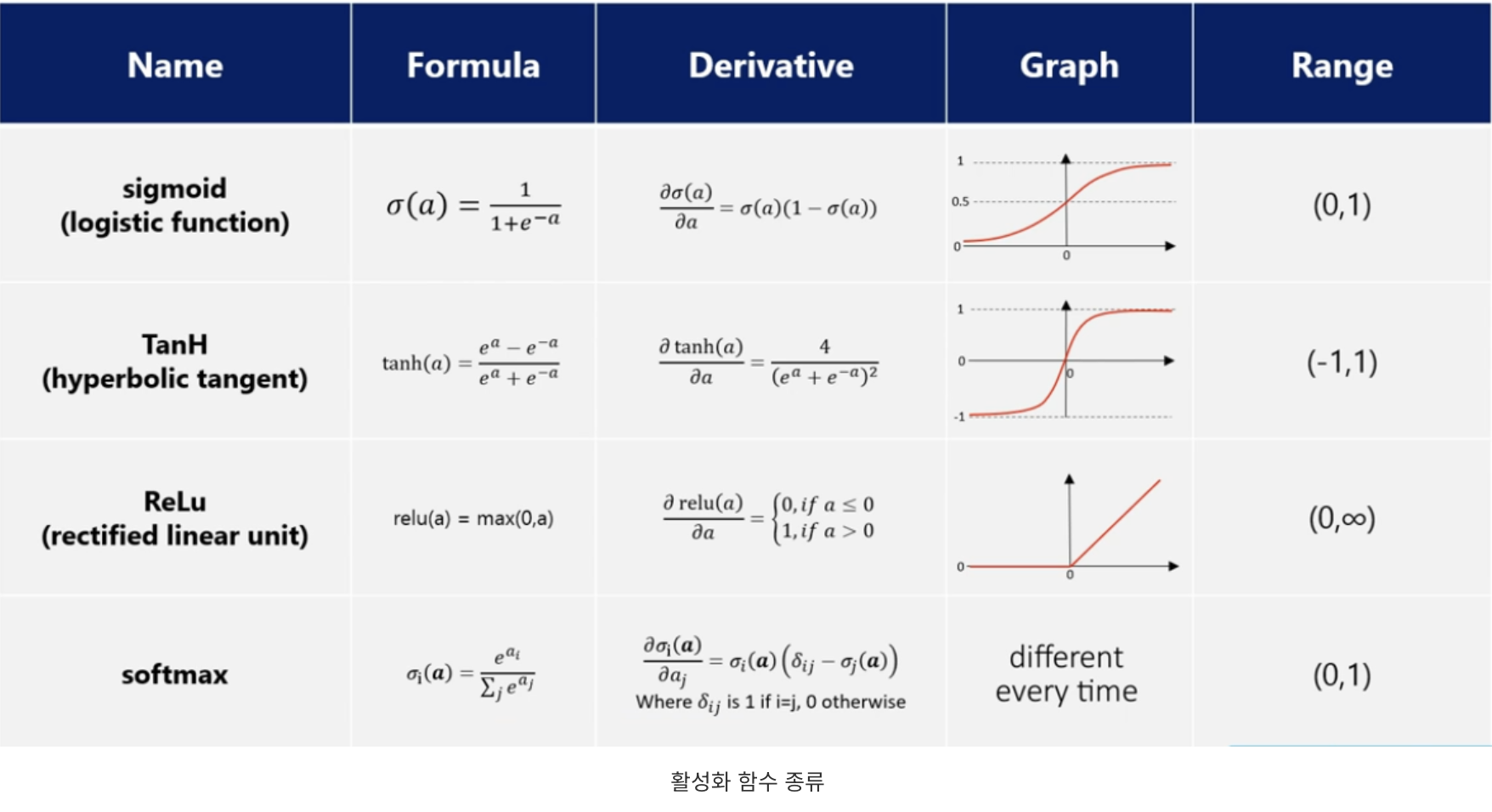
- sigmoid function
: vanishing gradient
: gradient descent 시 zig-zag 수렴
=> 결국 binary classification에 적용
-hyperbolic tangent
: vanishing gradient
-ReLU
: hidden layer에 사용
-softmax function
: multi classification에 적용
: sigmoid와 유사하지만 각 label의 합이 1이 되도록 출력함
2) loss function
손실 함수 : 네트워크 모델이 학습이 잘 되고 있는지 확인하는 지표
보통 분류에서는 cross entropy 사용
sofrmax & CE : 실제 class에 해당하는 softmax의 값에만 loss 부여
output. probabilities 실제값
0.7 0.01 0
1.3 0.02 0
5.1 softmax 0.90 1
2.2 0.05 0
1.1 0.02 0
C.E = -log(3번째 예측값) = -log0.9 = 0.105
CE와 squared-error
(1) CE
실제 class에 해당하는 softmax 값에만 loss 부여
아주 잘못된 값에는 큰 penalty를 부여
(2) squared-error
일반적으로 부여되는 패널티 비율은 큼 : 수렴이 힘듦
근데 또 엄청 잘못된 값에 큰 penalty를 부여하지 않음
3) optimizer
최적화 : 보다 최적으로 GD를 적용하여 최소 loss로 보다 빠르고 안정적으로 global optima를 찾아가도록 함
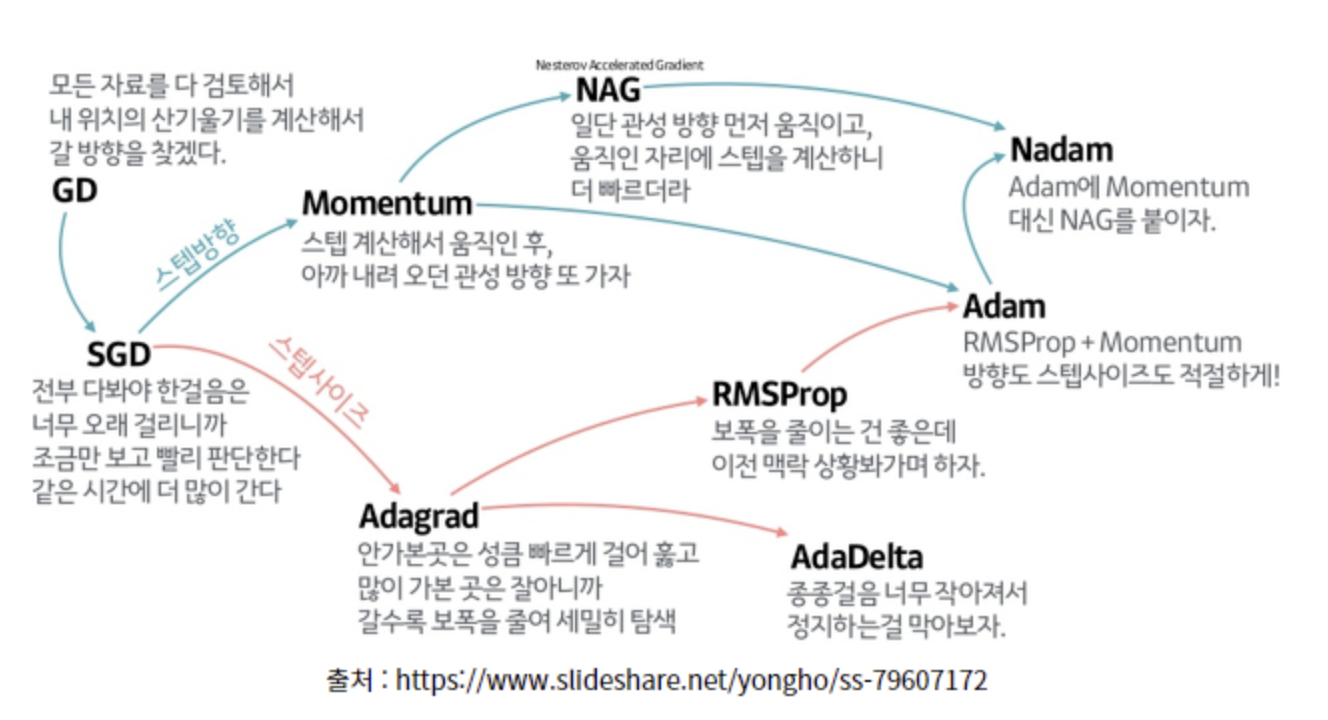
momentum : 관성 //gradient 보정
-과거 gradient를 감안하여 gradient update 진행
-zig-zag 수렴을 방지할 수 있음
-local minima에 빠졌을 때 도와줌 //한편으로는 과도한 update가 진행될 수 있음
Adagrad : adaptive gradient //lr 보정
-가중치 별 lr의 차이를 둠
-그동안 조금 변화된 가중치의 lr를 크게 가져감
-즉, 지금까지 많이 update된 변수는 적게, 적게 update된 변수는 많이 update 적용
-여기서 lr을 조절해주다보니 lr이 너무 작아지는 문제가 생김
RMSprop
-위 Adagrad의 lr이 너무 작아지는 문제 해결
-지수 가중 평균법 적용
-Adagrad와 다르게 '최근' update된 양을 고려함
ADAM
-RMSprop + momentum
-RMSprop과 같이 각 weight에 별도의 lr 값을 적용함과 동시에 gradient momentum까지 적용해줌
-두 수치 모두 지수 가중 평균을 적용함
'CNN 개념정리' 카테고리의 다른 글
| Gradient Descent, Back Propagation (0) | 2023.08.20 |
|---|---|
| [섹션 9] (0) | 2023.07.15 |
| [섹션 7] (0) | 2023.07.11 |
| CNN 전체 학습과정 (0) | 2023.07.10 |
| 섹션 5 (0) | 2023.07.05 |

