분류에서의 데이터 불균형 문제는 흔하지만 도전적인 작업이다.
각 클래스의 데이터 포인트 수가 중요하게 불균형을 보일 때, 분류기의 정확도는 저하된다.
이러한 imbalanced data 문제는 컴퓨터 비전, 의료 진단., 고장 탐지 및 기타 분야에서 쉽게 발견된다.
기계학습 알고리즘, ex 합성공 신경망의 성능은 불균형 데이터 조건에서 저하되고 분류 결과는 다수 데이터 클래스에 편향을 보인다.
이러한 imbalanced data는 주요 접근법 중 데이터 수준에서의 클래스 분포 재조정 즉 오버샘플링이나 언더 샘프링 및 앙상블 학습은 분류분류기의 의존하지 않는 일반적인 해결책이다. 이중에서도 소수 클래스에 대한 인공 데이터 생성을 결과로 하는 오버샘플링 기술은 이미지 분류에서 CNN 모델에 대한 클래스 불균형을 처리하는 가장 효과적인 방법이다.
여기서 잠깐 imbalanced data의 주요 접근법들을 살펴보자
https://chealin93.tistory.com/118
imbalance classification 다루는 방법 2
위에 그림에서 보듯이, 정상데이터는 파란색, 이상데이터는 빨간색, 나중에 test data로 쓰일 이상데이터들은 회색으로 표현이 됩니다. 잘 분류한다는 것은 파란색과 실제 이상관측치 분포를 구분
chealin93.tistory.com
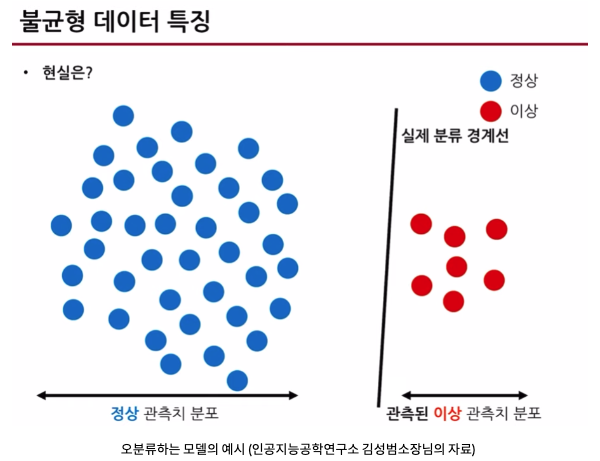
이러한 불균형 데이터의 경우 정상데이터로 분류를 잘하는 모델은 잘 만들 수 있지만 반면, 이상 데이터들을 잘 분류하는 모델을 만들었을 때 나오는 accuracy가 높은 값으로 나오더라도 믿을 수 없다.
class imbalance problem : 각 클래스의 데이터 개수비가 현저히 차이나는 것
이러한 문제들은 크게 2가지 접근 방법이 있다.
-Cost function based approach : rare class에 가중치 추가 or rare class를 잘못 분류하였을 때 cost를 조정하는 방법
-Sampling based approach : 데이터 자체를 늘리고 줄임 ex) upsampling, downsampling,SMOTE
* abnormal을 detection하는 classifier를 학습시키자
1. 적절한 metrix를 사용해 평가하기
2. resample the training set : under sampling and over sampling
3. 서로 다른 데이터셋으로 학습 후 앙상블
4. clustering하여 rare class와 모델 학습
5. 딥러닝을 이용한 학습과 클래스 가중치 주기
1. no information rate이 높을 경우 기본적으로 모델의 error와 함께 FN rate을 비교하여 전체 1 중 0이라고 예측한 비율을 줄이는 방향으로 해석해야함 (비정상 중 정상)

[no information rate이란]
가장 많은 값이 발견된 분류의 비율
ex) 실제값(reference)에 0이 4개, 1이 8개가 있다면 이러한 데이터를 분류하는 가장 간단한 알고리즘은 모두 1이라고 분류하 는 것
항상 1을 결과로 출려간다면 이 모델의 No Information Rate은 8 / 12=0.6667이다.
실제 분류 알고리즘은 피처들을 들여다보고 예측을 수행해야하므로 분류의 비율만 보고 결과를 출려가는 단순 분류알고리즘보 다 성능이 좋아야하므로 위 경우 모델을 만들 때, 0.6667은 반드시 넘어야하는 정확도이다.
위에서는 저렇게 말하긴 했지만 여기서는 accuracy가 no information rate보다 낮게 나왔다고 나쁜 모델이라고 할 수는 없다고 하네,,,?
예를 들면 달리기 선수에게 역도를 시켰을 때 능률이 평균 이하로 나온다고 해서 역도 선수를 운동 못한다고 할 수는 없다.
이때는 sensitivity와 specificity를 확인하여 모델이 정말 학습을 잘해서 분류한 것인지 아니면 하니의 classification으로 판단하는지 확인해야한다고 함
더불어 accuracy와 sensitivity, specificity 모두 낮은 모습을 보였지만 어느 정도 AUC값이 높게 나오면 무시해도 된다고 한다.
2. resample the training set : under sampling and over sampling
-under sampling(down sampling)의 경우, abundant class에서 무작위 추출을 통해 rare classs의 수와 1:1의 outcome 비율을 만들 수 있지만 데이터 수를 줄여 학습 효율이 낮아질 수 있음 + 중요한 정상 데이터를 잃어버리는 경우가 생길 수도 있음
-over sampling(up sampling)의 경우, outcome에서 rare class의 데이터를 증축시켜 abundant class의 데이터를 늘리는 방법이다. 적은 rare class에서 복원추출로 abundant class와 비율을 맞춰주는 것으로 무작위로 소수 데이터를 복제하여 늘리는 방법이 있어 정보 손실의 우려는 없지만 overfitting의 문제가 있다.
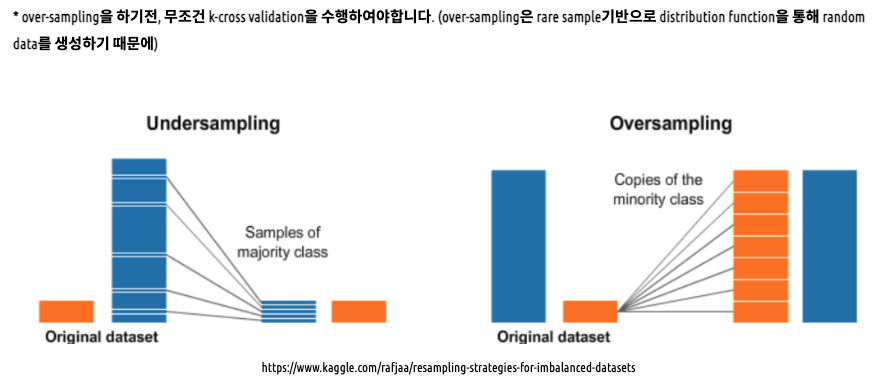
그렇다면 over sampling 시 데이터를 어떻게 늘리는가?
[SMOTE(Synthetic Minority Over-sampling Techique]
낮은 비율의 클래스 데이터를 최근접 이웃을 이용하여 생성함
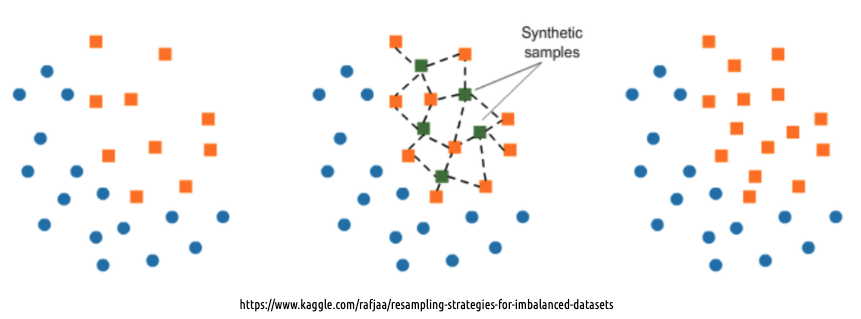
일반적으로 성공적으로 인스턴스를 생성하지만 소수 데이터들 사이에서 보간하여 작동하여 모델링셋이 소수 데이터들 사이 특 성을 반영하여 새로운 데이터 예측에 취약할 수 있다.
* SMOTE방법 python코드
mkjjo.github.io/python/2019/01/04/smote_duplicate.html
이처럼 resampling 방법이 다양한데 다른 리샘플링보다 월등히 좋다 이런 것 없기때문에 모두 시도해보는 것이 좋다고 함
3. 서로 다른 데이터셋으로 앙상블하기
가장 간단하고 쉬운 방법으로 rare class에 맞게 abundant class를 n개로 나누고 각각 abundant class와 rare class를 합쳐 n번의 모델 학습을 하여 결과를 합치거나 평균내어 사용한다.
4. clustering하여 rare class와 학습하기
클러스터링을 통해, aundant class를 r groups로 clustering함
즉 classes 개수를 r로 하고 각 그룹의 medoid를 가지고 rare class와 medoid로 학습한다.
5. 딥러닝을 이용한 학습과 class 가중치 주기
소수 클래스에서 정답을 맞추지 못한 경우, loss에 패널티를 주어 더 학습시킨다.
AUC를 최적화하는 방향으로 학습시킬 수 있다.
'DL 학습일지' 카테고리의 다른 글
| Overfitting 학습일지 (0) | 2023.09.11 |
|---|---|
| ham 10000 학습일지 (1) | 2023.08.20 |

