weakly supervised learning
1) 이미지 라벨링만을 가지고 학습을 진행하여 test의 Bbox를 찾고 싶은 경우
2) Bbox만을 가지고 학습하여 pixel label을 알고싶은 경우
즉, 내가 학습하는 것보다 알고싶은 것의 정보가 더 깊은 경우를 weakly supervised learning이라고 한다.





CAM의 한계
- GAP을 사용해야함 => 지막 convolution layer에만 저굥ㅇ가능
- 뒷부분은 fine tuning해주어야함
Gradient-weighted CAM : Grad-CAM


CAM에서는 가중치로 구하던 heatmap을 Gradient로 대신함

gradient의 픽셀별 평균을 각 feature map에 곱하여heatmap을 만들고 CAM과 마찬가지로 pixel-wise sum을 한 후 ReLU 함수를 적용하여 양의 가중치를 찾음
https://tyami.github.io/deep%20learning/CNN-visualization-Grad-CAM/
CNN visualization: CAM and Grad-CAM 설명
CNN 모델의 학습결과를 시각화하는 Weakly-supervised learning의 예시로 CAM과 Grad-CAM을 정리해봅니다
tyami.github.io
-------------------------------------------------------------------------------------
1. GAP : global average pooling
각 합성곱 레이어의 특징들의 평균을 구함
- 파라미터 개수 감소
- overfitting 감소
즉, 모델의 경량화와 오버피팅 방지, 성능 향상

- GMP : global max pooling
최대만을 수행하여 가장 구별적인 부분을 제외한 모든 이미지 영역에 대한 낮은 점수 부여
- GAP는 네트워크가 물체의 범위를 식별하도록 함, 평균을 구하여 모든 구별적 부분이 특정 맵의 출력을 줄여 해당 맵의 값 최대화 가능
즉, weakly-supervised object localization이 지역화에 더 유리
CNN은 이미지 수준의 레이블임에도 불구하고 물체 지역화 가능
= 적절한 기술을 사용해 물체 지역화 -> 이미지의 어떤 영역이 구별에 사용되는지 정확히 식별 사능
1) weakly-wupervised object localization : GAP 사용
2) visualizing CNN : fully-connected layer 아예 제거한 후 대부분 성능 유지 => network의 처음~끝 모두 이해 가능
2. CAM : class aactivation mapping

네트워크는 주로 합성곱 레이어로 구성됨
최종 출력 레이어 직전 GAP 적용
합성곱 신경망의 각 가중치를 합성곱 특징 맵으로 투영
3. weakly-supervised object localization
3.1 CNN에서 CAM을 사용한 효과
Alexnet, VGGnet, GoogLeNet 등에 대해 최종 출력 전 fully-connected layer 제거 후 GAP으로 대체한 후 fully-connected softmax 레이어 사용
-> 그 결과 GAP 이전 마지막 합성곱 레이어의 공간 해상도가 높을수록 네트워크의 localization 능력이 향상됨
=> 일부 네트워크에서 여러 합성곱 레이어를 제거함
ex) AlexNet: conv5 이후의 레이어 제거
=> mapping 해상도 = 13 * 13
VGGnet : conv5-3 이후의 레이어 제거
=> mapping 해상도 : 14 * 14
GoogLeNet : inception4 이후 레이어 제거
=> mapping 해상도 14 * 14
위 각 네트워크에 대해 3 * 3 크기, stride 1, padding 1, 2024 유닛으로 이루어진 합성곱 레이어 추가와 더불어 GAP 레이어와 softmax 레이어 추가 = 최종 네트워크 AlexNet-GAP, VGGnet-GAP 및 GoogLeNet-GAP이 생성
위 모델들과 분류를 위해 원래의 AlexNet [10], VGGnet [23], 그리고 GoogLeNet [24]과 Network in Network (NIN) [13]와의 접근 방식을 비교
지역화를 위해 원래의 GoogLeNet3, NIN 및 CAMs 대신 backpropagation [22]을 사용한 결과와 비교
+ 평균 풀링과 맥스 풀링을 비교하기 위해 전역 맥스 풀링 (GoogLeNet-GMP)을 사용한 결과도 제공

원래 network와 GAP network 성능 비교
=> 대부분의 경우 추가 레이어 제거시 소량의 성능 하락 발견
하지만 대부분의 성능 보존 성공
+ GoogLeNet-GAP 및 GoogLeNet-GMP가 예상대로 분류에서 유사한 성능을 보임
네트워크가 지역화에서 높은 성능을 달성하려면 객체 범주와 경계 상자 위치를 정확히 식별해야함 즉, 분류 수행이 잘 되어야함
Localization이 잘 수행되려면 바운딩 박스와 해당 객체 범주를 생성해야함
CAMs에서 바운딩 박스를 생성하려면 히트맵을 세그먼트화 해야함
1) CAM의 최대 값의 20% 이상의 영역을 세그먼크화함
2) 세그먼트화된 맵에서 가장 큰 연결 구성 요소를 포함하는 바운딩 박스를 가져옴
3) 이를 상위 5개 예측 클래스 각각에 대해 수행함


위의 방법으로 bbox 설정하여 학습시킨 결과,
GAP 네트워크가 기존보다 우수한 성능을 보이는 것 확인 가능
특히나 GoogLeNet-GAP가 43%의 최소 지역화 오류를 달성하였는데 본 네트워크가 주석이 달린 바운딩 박스에서 훈련된 것이 아니라는 점이 주목할 만 하다
backpropagation보다 CAM 접근방식이 더 효과적임
GAP가 GMP보다 효과적임을 알 수 있음
접근 방식을 weakly supervised와 fully-supervised 비교를 위해 GoogLeNet-GAP 성능을 ILSVRC 테스트 세트에서 평가했다
Bbox 전략은 top 1st와 2nd 예측 클래스의 클래스 활성화 맵에서 두 개의 바운딩 박스와 top 3rd 예측 클래스에서 하나의 느슨한 바운딩 박스를 선택함 => 이 휴리스틱은 검증 세트에서 성능 향상을 시키는 데 도움이 됨
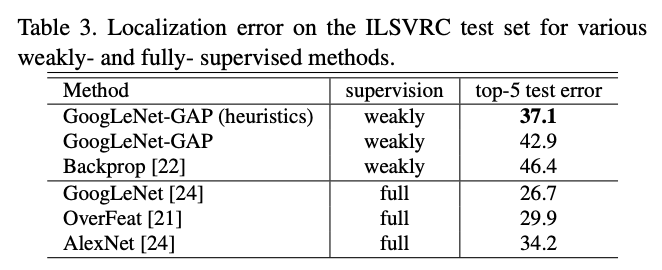
휴리스틱을 사용한 GoogLeNet-GAP은 weak와 fully 비슷하지만 아직 많은 발전의 여지가 있다
GAP을 이용한 CNN에 대한 Class Activation Mapping은 분류로 훈련된 CNN이 바운딩 박스 주석을 사용하지 않고도 객체 지역화를 수행할 수 있음, CAM은 주어진 잉미지에서 예측된 클래스 점수를 시각화하게 해주며 CNN이 감지한 구별적인 객체 부분 강조함
'Paper Review > Computer Vision' 카테고리의 다른 글
| [Paper Review] U-Net: Convolutional Networks for Biomedical Image Segmentation (1) | 2024.02.28 |
|---|
