object detection : 객체 탐지
주어진 이미지 내 사용자가 관심 있어하는 객체 탐지
ground truth : 이미지 속 객체의 위치에 대한 개발자의 정답
bounding box : 이미지 속 객체 위치 표시 상자
"성능이 좋은 객체 탐지 알고리즘" = gound truth와 가장 가까운 Bbox를 표현한 모델
IoU : intersection over union
IoU값이 높을 수록 성능 좋음
You Only Look Once
- 이미지 전체를 한번만 본다
- 실시간 object detection 가능
복잡한 파이프라인 X => fast
[알고리즘 작동 방식]
1) input 이미지 N*N 그리드로 분할
2) 각 그리드마다 이미지 분류 및 지역화 작업 수행
객체 위치 확인 및 식별해야하는 객체에 Bbox 그림
3) Bbox와 각 객체의 class 확률을 통해 객체 인식 및 예측
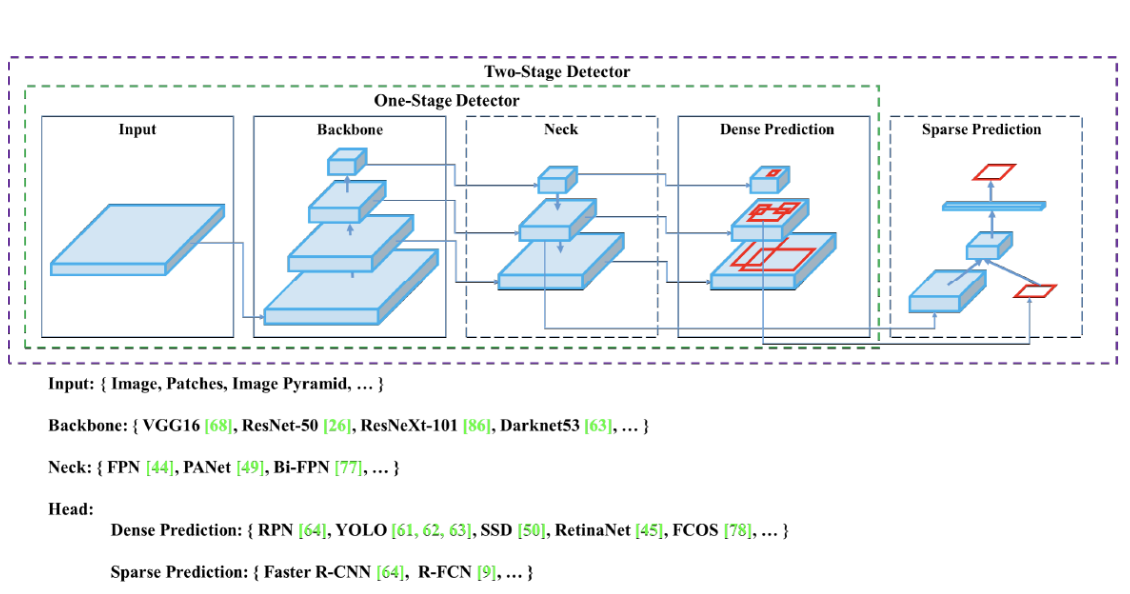
backbone과 head로 구성됨
backbone : 입력이미지 => feature map
head : backbone에서 추출한 feature map의 location 작업 수행

YOLOv5
단일 단계 방식의 객체 탐지 딥 러닝 기법
매우 빠른 속도와 추론 과정으로 real time object detection 가능
=> Fast regioin based convolution neural networks(Fast R-CNN) 등의 기존 실시간 객체 탐지 모델보다 뛰어난 성능 보유
이미지 전체를 보고 물체의 일반적인 부분을 학습하여 단일 대상의 특징 뿐 아니라 이미지 전체의 맥락을 학습함
더불어 대상의 일반적 특징을 학습하여 다른 영역으로의 확장에도 뛰어난 성능을 보인다
YOLO 성능 평가 방법

confusion matrix의 precision, recall => P-R curve
1) P-R curve
해당 객체가 특정 class일 확률에 따른 각 객체 분류 곡선을 그려 object detector의 성능 평가 적용
특정 class의 object detector는 재현율 증가하면서도 정밀도가 높게 유지되는 경우, 양호한 성능으로 간주
2) 모든 ground truth objects를 찾아 관련 object만을 식별할 수 있는 detector 찾기
=> 즉 불량 object detector의 경우, 모든 실제 객체를 검색하기 위해서는 탐지된 object의 수를 늘려야함
= recall ↑ =precision ↓
=P-R curve에서 precicion 증가로 시작하여 recall 증가에 따라 precision이 감소하는 이유
3) AP : average precision
정밀도 * 재현율 곡선 아래 면적을 계산 => 서로 다른 detector 비교에 적합


여러 class에 대한 AP를 구하며 평균값을 구함 => mAP
mAP50 = IoU 0.5이상 값을 가지는 prediction을 True Positive로 설정한 클래스 별 AP값
mAP50-95 = IoU 0.5부터 0.05 간격으로 0.95까지 설정 된 값 이상의 데이터에 대해서 prediction을 True Positive로 설정하고 각각 독립적으로 수행한 후(AP50, AP55, ...AP95) 이를 평균한 클래스 별 AP값

각 빨간색 Bbox 옆 백분율 = 이 object class에 대한 detection confidence


- 단일 겹침 => ground truth bbox와 예측 bbox IoU 계산
IoU >= 0.5 (TP = 1, FP = 0)
IoU < 0.5 (TP = 0, FP = 1)
- 복수 겹침 => ground truth와 예측 bboxs 간 IoU 게산
- IoU >= 0.5 & 제일 큰 예측 bbox 선택 (TP=1)
- 그렇지 않으면, TP = 0, FP = 1
- IoU 동일 => confidence 가장 큰 예측 box 선택
선택 예측 bbox : TP = 1, FP = 0
선택되지 않은 예측 bbox : TP = 0, FP = 0
Acc TP = Acc TP / (Acc TP+ Acc FP)
Acc FP = Acc TP / ground truth = Acc TP / 15
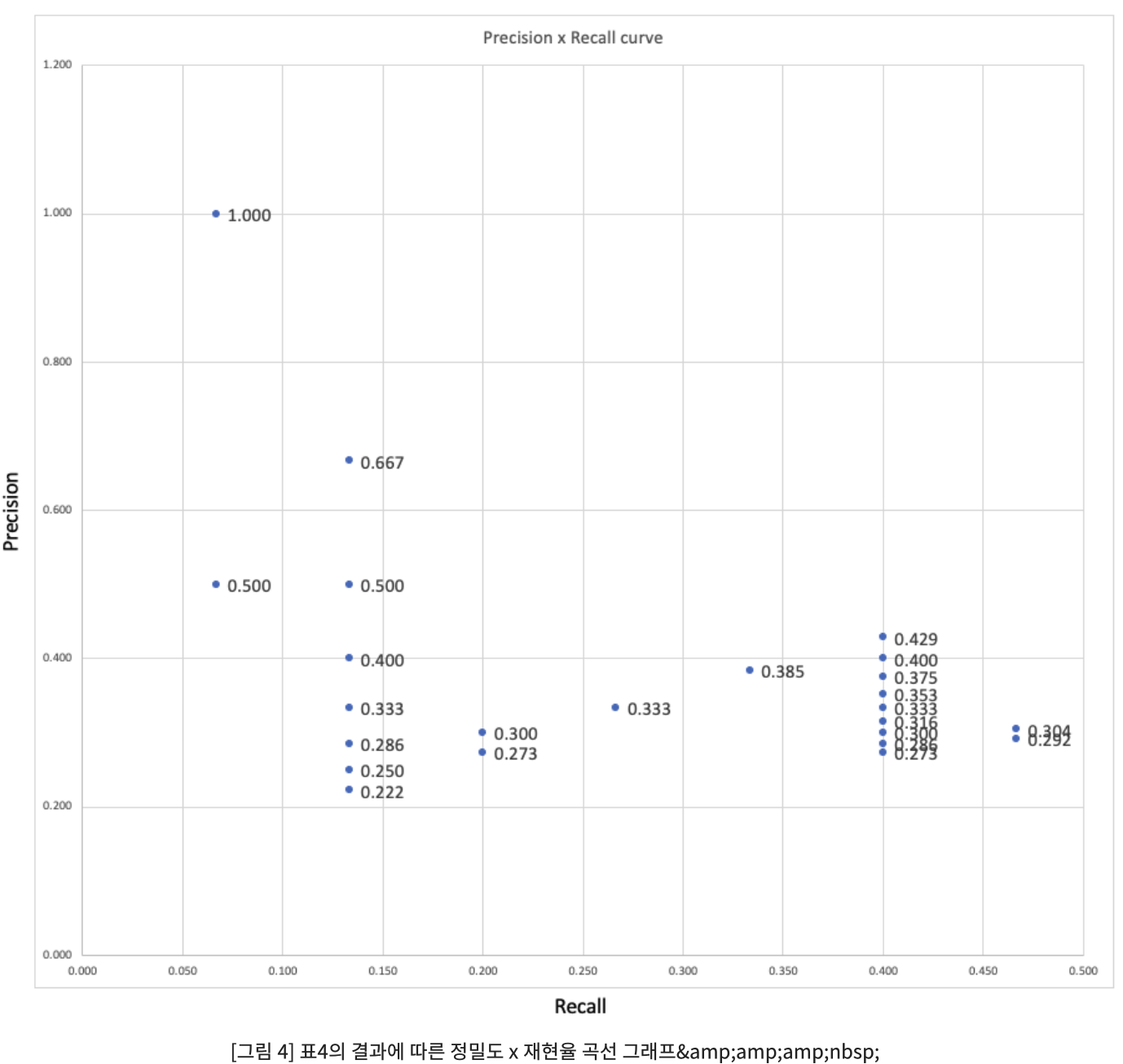
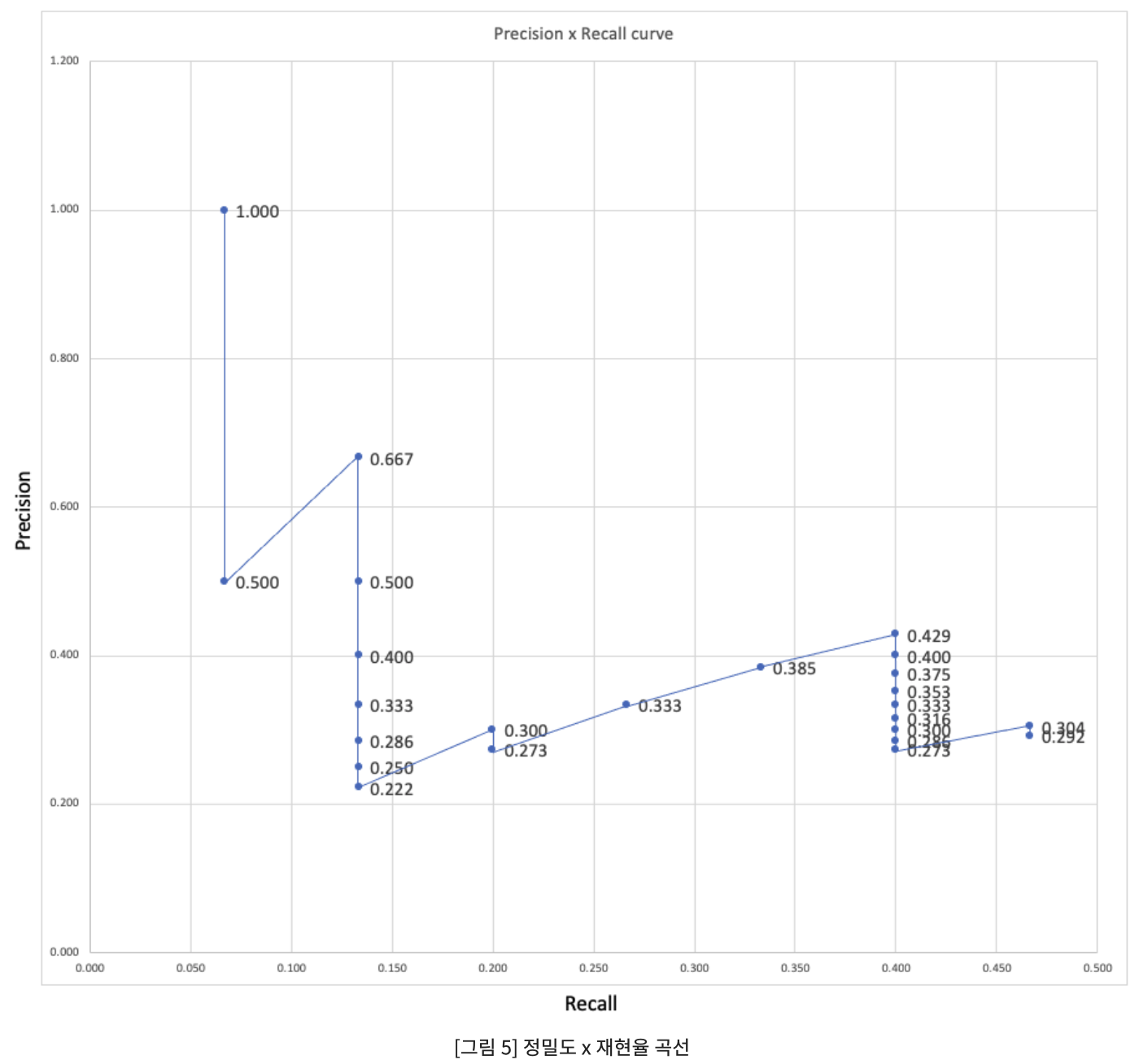


AP=1*(0.067-0) + 0.667*(0.133-0.067) + 0.429*(0.4-0.133) + 0.304*(0.467-0.4) = 24.59%
여러 class에 대한 AP를 구하며 평균값을 구함 => mAP
OC opendataset 학습 결과


Reduce LRonPlateau가 yolo에서는 lrf로 조절된다고 보면됨
설정값:
- 초기 학습률 (lr): 0.01 //default
- 최종 학습률 (lrf): 0.1
계산:
- 최종 학습률 = 초기 학습률 * lrf = 0.01 * 0.1 = 0.001
학습률 더 낮출 경우, 성능 ↓

normal과 abnormal을 헷갈리는 일은 거의 없음을 알 수 있음
but, normal, abnormal과 background 사이 detection이 잘 안됨
=> 여러 이유가 있지만 우리 데이터의 경우 background 이미지가 복잡함
이 부분을 같이 얘기하면서 해결했으면 함
Q) 내가 적용한 학습 데이터 라벨에는 back ground가 없었는데 confusion matrix에는 back ground까지 3개 라벨 존재
back ground : 탐지할 객체가 없는 데이터
보통의 객체 검출 알고리즘은 '배경' 라벨을 명시적으로 포함시키지 않더라도 내부적으로 고려한다
객체와 비객체 영역을 구분하는데 back ground class가 도움이 되기 때문
+ yolo v5의 경우 성능 향상을 위해 back ground 이미지를 넣기도 함 (=> FP가 감소함)
'DL 기본개념' 카테고리의 다른 글
| Bayes' theorem & VAE (2) | 2024.03.01 |
|---|---|
| Wavenet 논문 전체 내용 (1) | 2023.11.01 |
| CV Task (0) | 2023.10.09 |
| [RNN, LSTM, GRU] (3) | 2023.10.02 |
| GAN, WGAN, WGAN-GP (1) | 2023.09.19 |


