강화학습
어떠한 모르는 환경에서 동작하는 에이전트가 있을 때, 에이전트가 현재 상태에서 향후 기대되는 누적 보상값이 최대가 되도록 행동을 선택하는 정책을 찾는 것

-> 마르코프 결정 과정 : MDP 사용
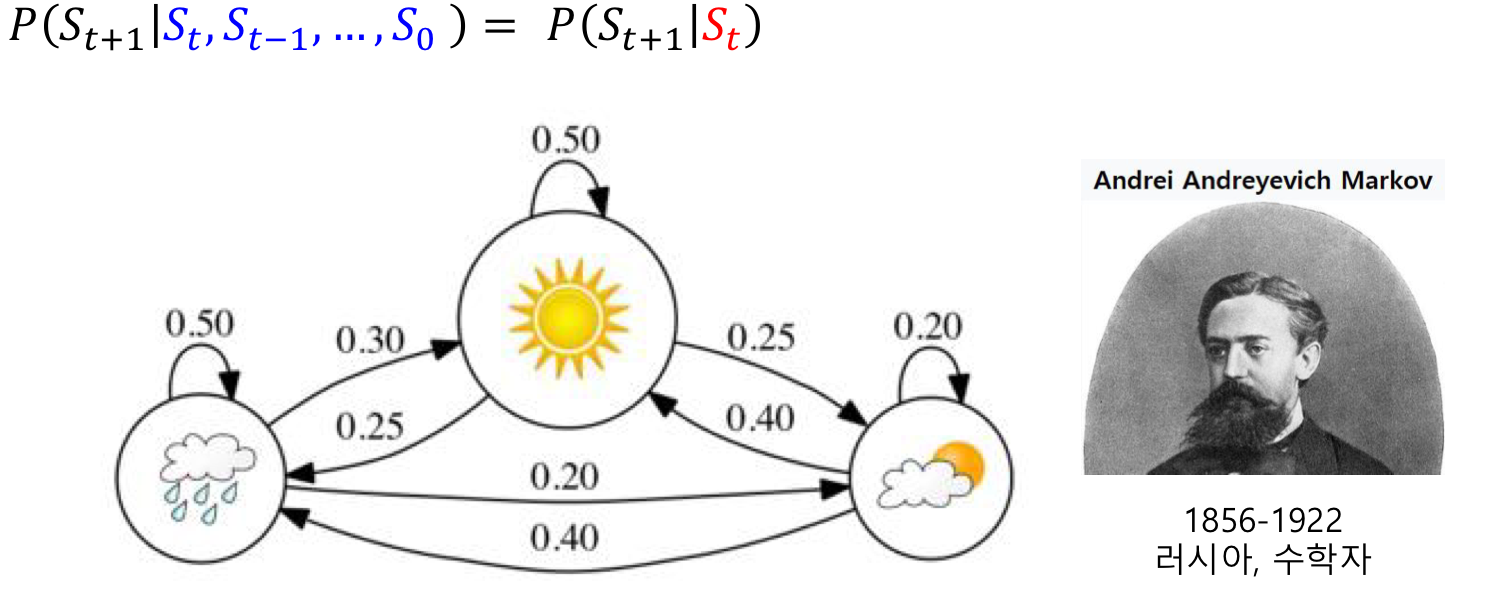
마르코프 결정 과정 : markov decision process
상태 전이가 현재 상태인 St와 입력(행동) At에 의해 확률적으로 결정되는 모델
-> 마르코프 모델
미래 상태 St+1은 현재 상태 St에만 영향을 받으며 과거 상태 St-1,...에는 영향을 받지 않는 시스템에 대한 확률 모델


=> 강화학습의 목적 : 기대 누적 보상값이 최대가 되도록 하는 정책을 찾는 것
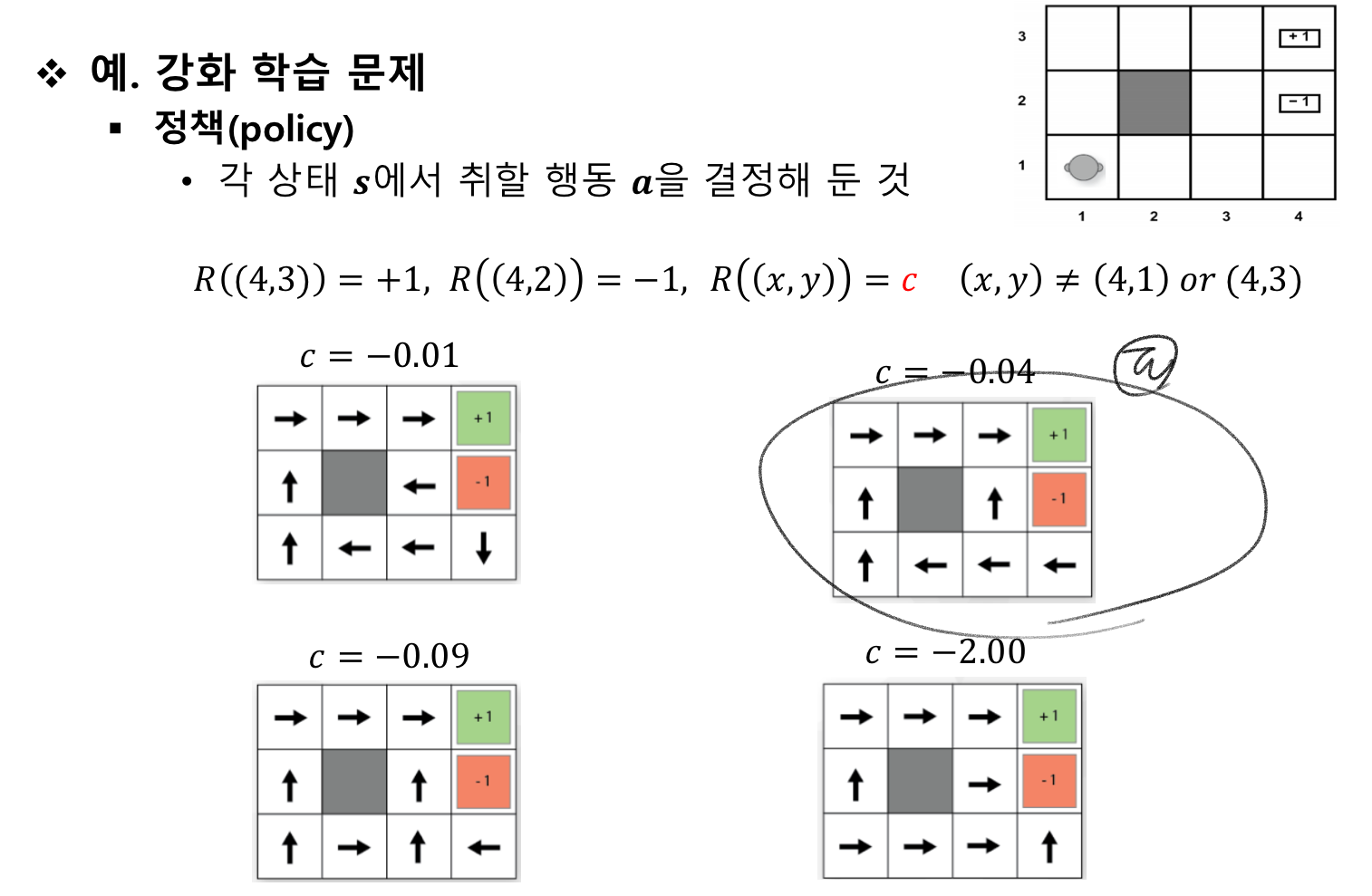
정책이란?
각 상태에서 선택할 행동을 지칭함

누적 보상치
- 단순 합계 : 단순하게 연속적으로 보상치를 더함
- 할인 누적 합계 : 할인율을 고려함 (가까운 보상에 더 큰 가치 부여)
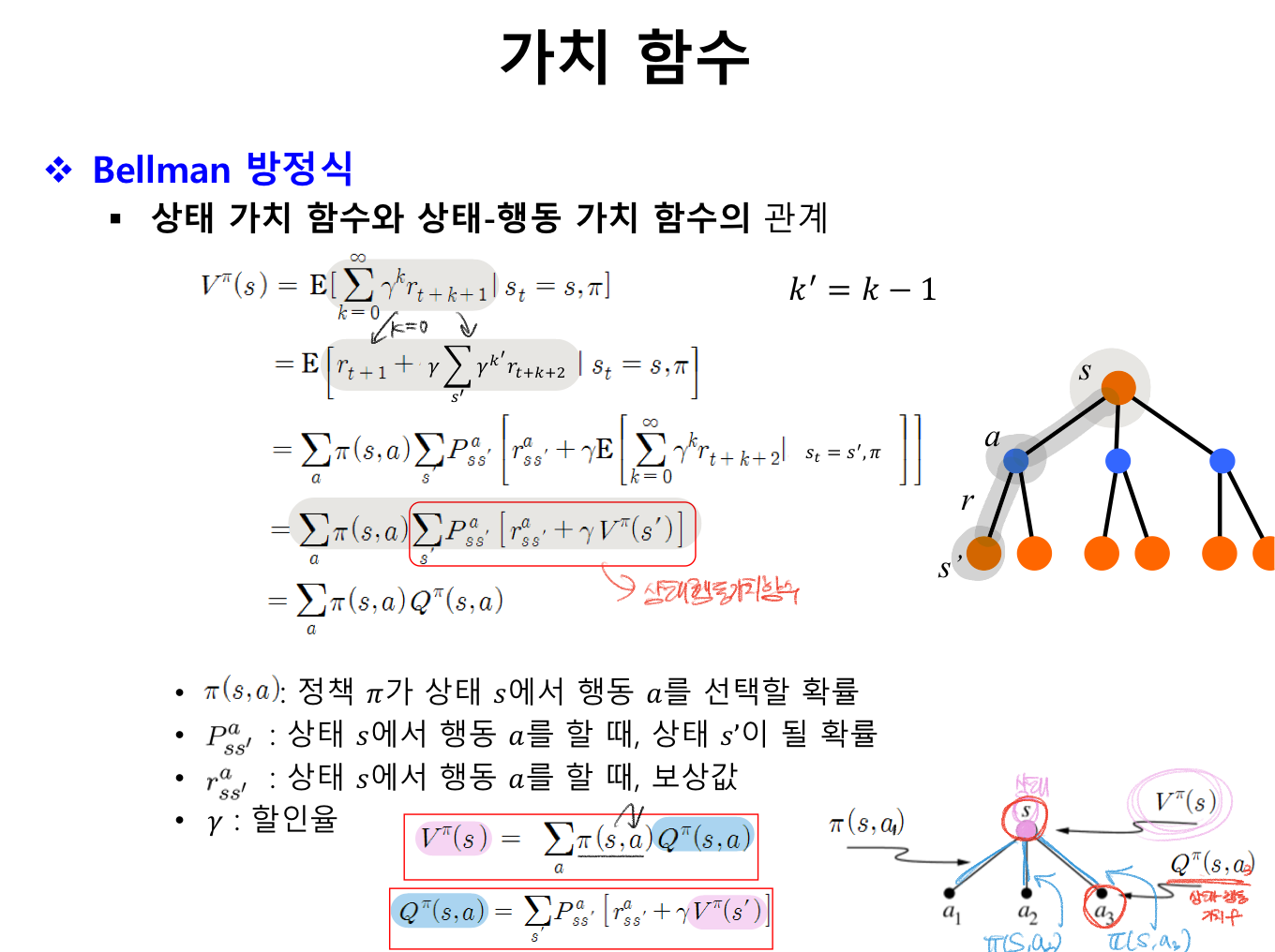
가치함수 -> 두 가지 종류 잘 알아두기
1. 상태 가치 함수
상태 s에서 시작해 정책 π에 따라 행동을 할 때 얻게 되는 기대 보상
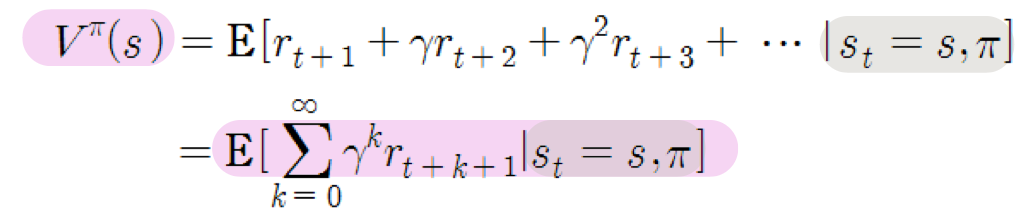
2. 상태-행동 가치 함수
상태 s에서 행동 a를 한 후, 정책 π에 따라 행동을 할 때 얻게 되는 기대 보상


가치 함수 계산 방법
동적계획법 : dynamic programming : DP
- 모든 상태에 대한 섭렵 & bellman 방정식 성질을 사용해 가치 함수 계산
=> 1) 정책 반복 학습, 2) 값 반복 학습 알고리즘
최적 정책π* 과 최적 상태 가치 함수 V*
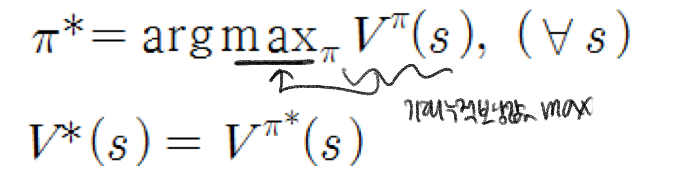
bellman 최적 방정식
최적 정책에 따른 가치 함수들이 만족하는 성질

정책 평가
주어진 정책 π를 따를 때, 각 상태에서 얻게 되는 기대보상 값 계산 V^π 계산
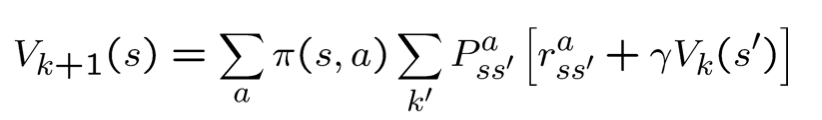
-> 임의의 가치함수에서 시작해 Vk가 수렴할 때까지 반복한다
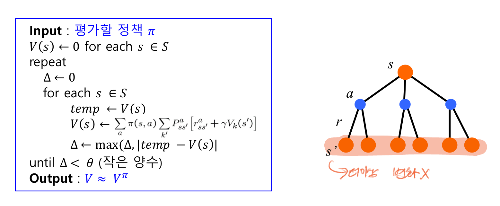
정책 반복 학습 알고리즘
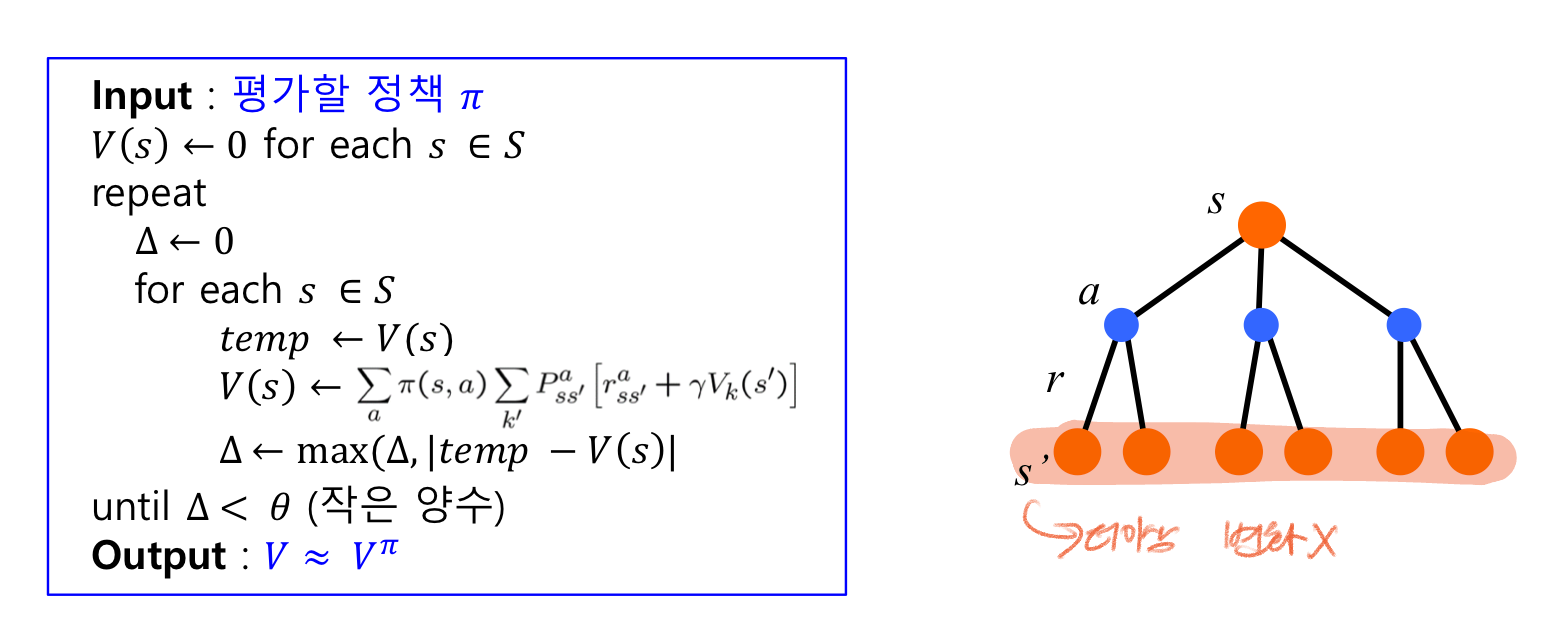
정책 개선
-> 상태 가치 함수 V(s)값으로부터 정책 π를 결정함

값 반복 학습 알고리즘

위의 정책 반복, 값 반복 학습 알고리즘의 정확한 MDP 모델을 알지 못하는 경우가 많기 때문에
Q-learning 알고리즘을 적용한다.


=> 가치 q 값을 모르는 상태에서 시작, 다음 상태에서의 q는 알고 있다! => 계속하여 상태를 학습하며 q를 학습한다. q를 알면 이를 최대화하는 정책을 찾을 수 있다
'강의 > 인공지능개론' 카테고리의 다른 글
| 하이브리드 지능시스템 (1) | 2024.06.11 |
|---|---|
| SVM (0) | 2024.06.07 |
| 기계학습 : 추가 신경망 (1) | 2024.06.05 |
| 기계학습 2.Decision Tree (1) | 2024.06.02 |
| 기계학습 1 (2) | 2024.05.10 |



