wavenet
dilated causal convolution 기반의 오디오 파형을 생성하는 신경망
dilated convolution
receptive field : filter가 한 번에 계산하는 영역 //receptive field가 커질 수록 output 계산 시 사용되는 정보의 양이 많음
정보의 양 증가 => 학습량 증가 => 연산량 증가
receptive field를 크게 만들어 커버 영역을 크게 만듦 & 연산량 증가
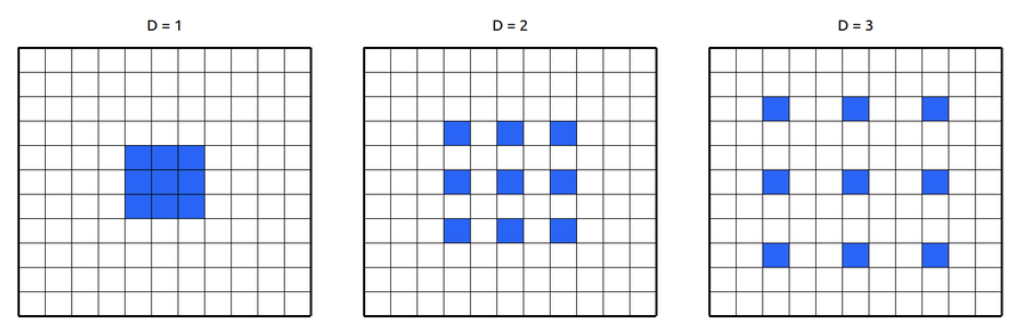
dilation 크기 증가 => input 간격 증가 => receptive field 증가
but, 연산량 증가 X
필터를 sparse하게 추출하는 경우 물론 손실은 있겠지만 receptive field의 크기가 중요한 경우 작동 good
ex) audio 데이터의 경우 1초당 16000~22500개 sample 존재
dilated convolution을 사용해 몇 개의 layer를 통해 많은 sample 커버 가능
causal convolution
음성 = 시계열 데이터
10000번째 샘플 생성을 위해 10001번째 데이터 사용 X
보통 이런 경우 시계열 데이터 모델링을 위해 RNN 계열을 사용하게됨
but, 시간이 오래 걸림
대안 : CNN을 시계열 모델링에 사용
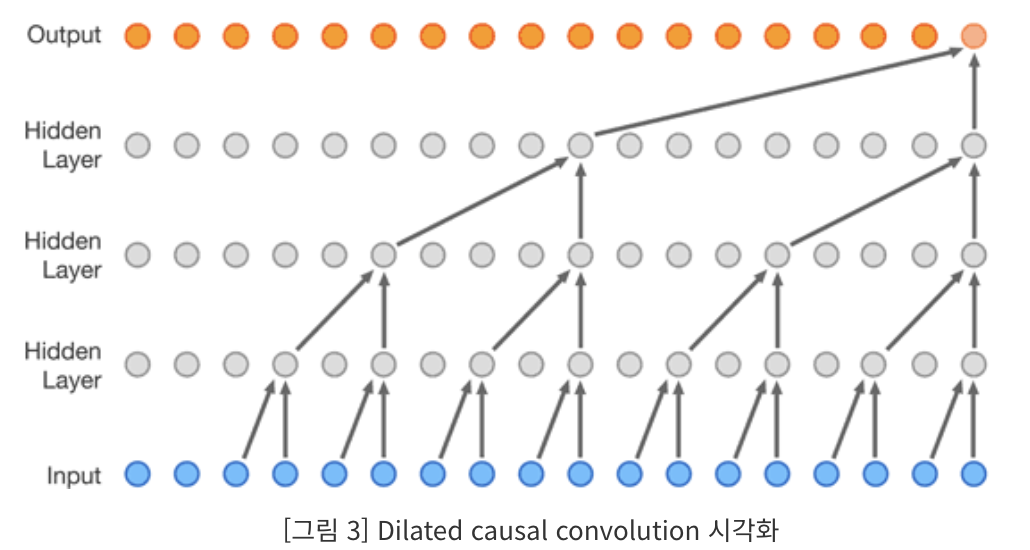
dilated causal convolution
wavenet : 음성을 고품질로 합성해내기 위한 모델
시계열 데이터인 음성을 효과적으로 모델링 하기 위해 순소를 고려한 구조를 통해 모델 학습
=> dilated & causal 개념 => 엄청난 크기의 receptive field를 갖는 모델 구조
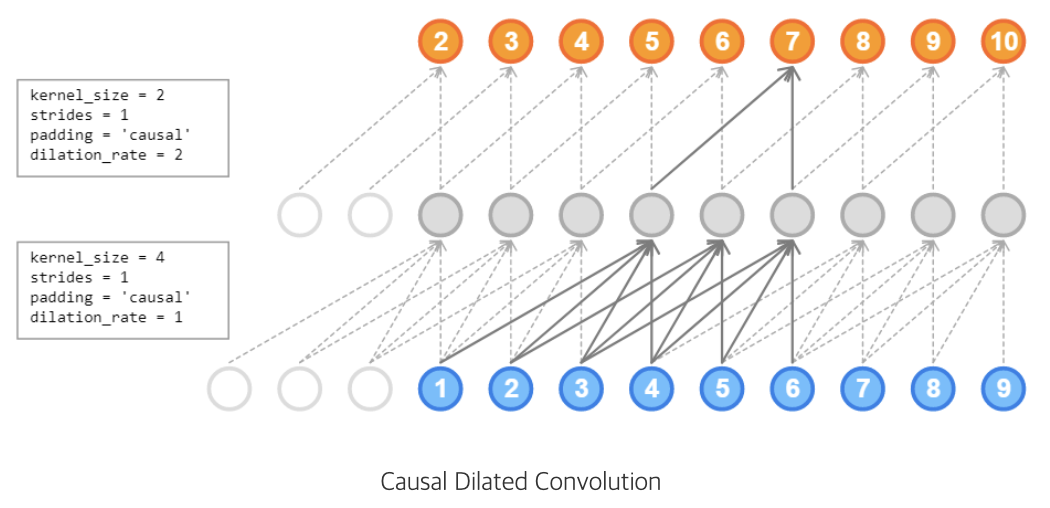
=> 필터가 일정한 간격으로 input을 건너뛰어 큰 영역에 적용되는 인과합성곱
- TTS(text-to-speech) 분야에서 이전엔 보고된 적 없던 상대적으로 자연스러운 음성 생성 모델
- 매우 넓은 receptive field를 보여주는 dilated causal convolution 기반의 새로운 아키텍쳐
- 발화자 특성을 조절하였을 때, 단일 모델로도 다른 발화자의 음성 생성 가능
- 작은 음성 인식 데이터셋으로도 강력한 결과를 보여주며 음악 등 다른 분야에서도 생성 가능
음성 파형에 대해 직접 작동하는 생성 모델
파형 : conditional probability로 분해하여 표현 가능
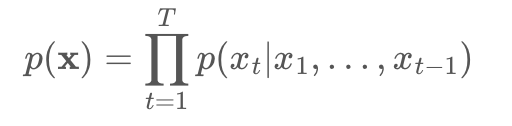
각각의 음성 샘플 Xt : 이전 모든 시간 단계의 샘플들을 정보로 갖음
auto-regressive model (AR model)
출력 변수가 이전 값과 확률적인 항에 대해 선형적으로 의존함
음성은 시계열 데이터이기 때문에 causal convolution을 통해 모델링 순서를 위반하지 않도록 조절
t 시간의 예측값 p(Xt+1lX1,...,Xt)는 어떤 미리 시간대 정보를 이용하지 않음
//즉 t 시간에서 생성하는 결과는 오직 과거 결과만을 참고함
학습 단계
모든 시간 단계의 ground truth X를 알고 있음
parallel 학습 가능
추론 단계 : inference
이전 단계에서 예측된 샘플 결과를 현재 샘플 예측을 위한 input으로 넣음 : auto-regressive
causal convolution을 적용하는 동시에 큰 수용 영역을 위해 dilated convolution을 이용함

pooling
convolution 연산 후 취할 값을 정하는 층
max pooling, average pooling
stride
convolution 연산에 이동하는 kernel 이동 단위
dilated convolution은 pooling&stride와 비슷하지만 출력값이 입력값과 같은 크기를 가진다는 점이 차이
즉, 연산량이 증가하지 않음
=> 더 적은 계층들로도 큰 수용영역의 network 처리가 가능해짐
네트워크 전체 입력 해상도와 계산 효율성은 유지됨
dilation은 모든 계층에서 끝까지 2배로 증가
1,2,4,8,....
softmax distribution
개별 오디오 샘플에 대한 조건부 분포를 모델링하기 위한 방법
그 중에서도 softmax는 잠재적으로 연속적인 데이터에서 더 좋은 성능을 보임
더 유연하고 형태에 대한 가정을 하지 않았기때문
일반적으로 오디오 : 16bit 정수값의 sequence로 저장됨 (시간당 1개)
softmax 계층 : 모든 확률값 모델링 (시간 당 56,636개 확률 계산)
이를 계산하기 위해 25개 가능한 값으로 quantization 적용
: 무한대 값을 유한한 몇가지 대표값으로 바꿔줌 (ex) 0.5 => 1 )
non-linear quantization은 단순한 linear quantization보다 더 잘 재구성함
특히나 음성 분야에서 quantization 이후 재구성된 신호가 기존의 오디오와 굉장히 유사하게 들림
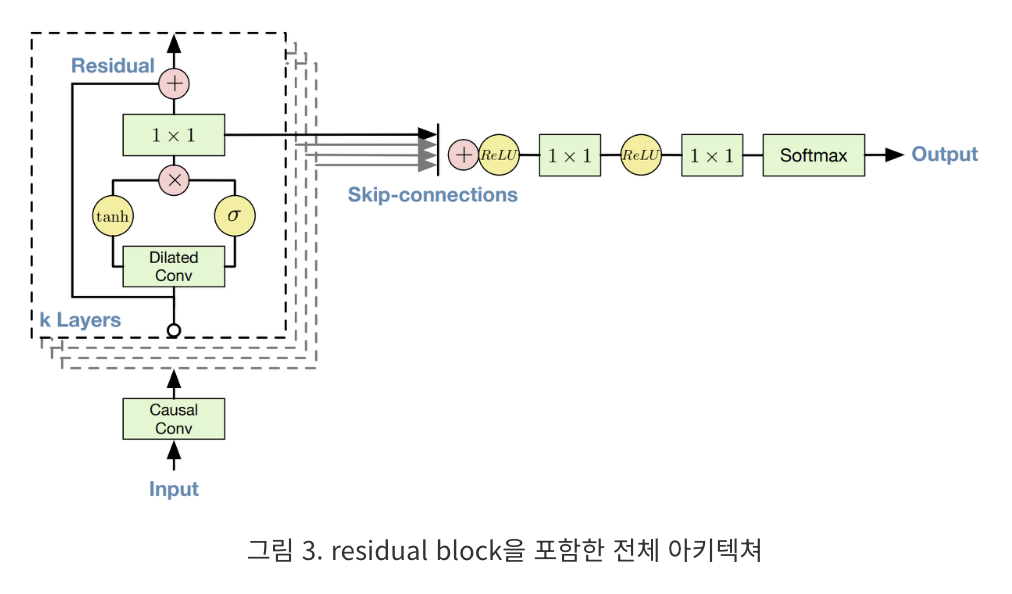
gated activation units
gated pixelCNN에서 사용된 gated activation unit 사용
residual and skip connection
for 수렴 속도 향상, 모델의 depth 향상을 위해 residual connection과 매개변수화된 skip connection을 네트워크 전체에 사용함
conditional wavenet
wavenet은 추가적인 입력값 h가 주어지면 오디오의 조건부 분포를 모델링할 수 있음
입력 변수들을 통해 필요한 특성을 가진 오디오를 생성하도록 wavenet 설정 가능
더불어서 TTS에서는 추가적인 입력값으로서 텍스트에 대한 정보를 입력할 필요가 있음
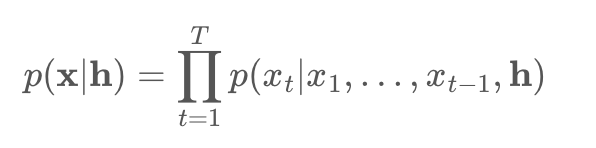
텍스트에 대한 정보 입력 방식 1) global conditioning
모든 시간 단계에 걸쳐 출력값에 영향을 주는 speaker embedding과 같은 단일 latent representation 사용
고차원 데이터를 이용한 문제 해결 시 실제 모든 feature를 사용할 수 있지만, 실제 공간:observation space보다 관찰 대상을 잘 설명할 수 있는 잠재 공간:latent space를 알아낼 수 있음 => 잠재공간을 아는 것 = '차원 축소'
잠재 공간 : latent representation or coding
텍스트에 대한 정보 입력 방식 2) local conditioning
언어적 정보와 같이 오디오 신호보다 낮은 sampling frequency의 시계열 시퀀스 ht 사용 가능
언어적 정보의 시퀀스를 오디오 신호와 동일한 해상도로 upsampling 하기 위해 transposed convolution 네트워크 사용
이렇게 upsampling된 시계열 시퀀스에 activation unit이 적용됨
context stacks
wavenet 수용 영역 크기를 키우기 위한 여러 방법 중 보완적 방법으로 오디오 신호의 긴 부분을 처리하는 작은 context stack으로 분리하여 사용하며 오디오 신호의 짧은 부분만을 처리하는 더 큰 wavenet을 부분적으로 조절함
저불어 hidden unit 수와 길이를 다양하게 하여 context stack 사용하는 방법도 있음
-wavenet 오디오 모델링 성능 측정을 위한 3가지 문제-
1) multi-speaker speech generation
발화자의 id를 모델에 one-hot 벡터의 형태로 집어넣어 생성된 음성의 목소시 조절
발화자 정보의 OHE를 조절하여 단일 wavenet을 통해 어떤 발화자의 음성이든 학습이 가능하다
단일 발화자로만 학습하는 것보다는 여러 발화자로 학습하는 것이 더 나은 성능을 보임
이는 wavenet 내부 representation이 여러 발화자 사이에 공유되고 있음을 알 수 있음
2) TTS : text-to-speech
TTS 문제를 위해 wavenet은 입력 텍스트로부터 추출한 언어적 특징을 부분적으로 조절함
또한 언어적 특징에 추가 변수를 통해 피치 정보 조절할 수 있도록 학습함
- auto-regressive한 음성 추출
- causal 필터를 통합해 수용영역의 지수적 깊이 증가
- 입력 값에 대해 global, local한 방식으로 조절 가능
- TTS에 wavenet 적용 시, 성능 유망
------------------- 논문 정리 ---------------------------------------------------------------------
WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
wavenet : a deep neural network for generating raw audio waveforms
완전히 확률적이며 자기회귀적 모델
각 오디오 샘플의 예측 분포는 이전 모든 샘플에 조건부로 설정되면서도 초당 수만 개 샘플을 가진 데이터를 효율적으로 훈련할 수 있음
Introduction
픽셀이나 단어들의 결합확률을 조건부 분포의 곱으로 모델링하는 신경 구조체 사용해 최첨단 생성 달성
위 구조는 수천개 무작위 변수(: like PixelRNN) 64*64에 대한 분포를 모델링 할 수 있는 능력을 가짐
논문 목적
위 구조와 유사한 접근법으로 매우 높은 시간 해상도를 가진 광대원 원시 오디오 파형 생성에 성공 할 것인가?
PixelCNN 구조를 기반으로 하는 오디오 생성 모델 WaveNet 소개
- WaveNets가 TTS 분야에서 인간 평가자들에 의해 평가된 바와 같이 이전에 보고된 적 없는 주관적 자연스러움을 가진 raw audio waveform 생성할 수 있음
- raw audio waveform 생성에 필요한 장기간 시간적 종속성을 다루기 위해, 매우 큰 수용 영역을 가지는 dilated causal convolutions에 기반한 새 구조 개발
- 화자 신원에 따른 조건에 따라 단일 모델을 사용해 다양한 목소리 생성 가능
- 같은 구조가 소규모 음성 인식 데이터 세트에서 강력한 결과를 보여줌, 음악 등 다른 오디오 형태 생성에 사용될 때 유망함
논문의 목적 : PixelCNN 구조를 기반으로 하는 오디오 생성 모델 WaveNet 소개
1) wavenet

각 오디오 샘플 Xt는 이전 모든 시간 단계의 샘플에 대한 조건을 가짐
PixelCNNs와 유사하게 조건부 확률 분포는 합성곱 레이어 스택으로 모델링됨
네트워크에 풀링 레이어 존재 X, 모델 출력은 입력과 동일한 시간 차원을 가짐
softmax layer를 사용해 Xt에 대한 범주형 분포 출력
데이터에 대한 lod-likelihood를 최대화하도록 매개변수 최적화
: 로그 가능도는 실용적이기 때문에 검증 세트에서 하이퍼파라미터를 조정, 모델 과적합인지 쉽게 측정 가능
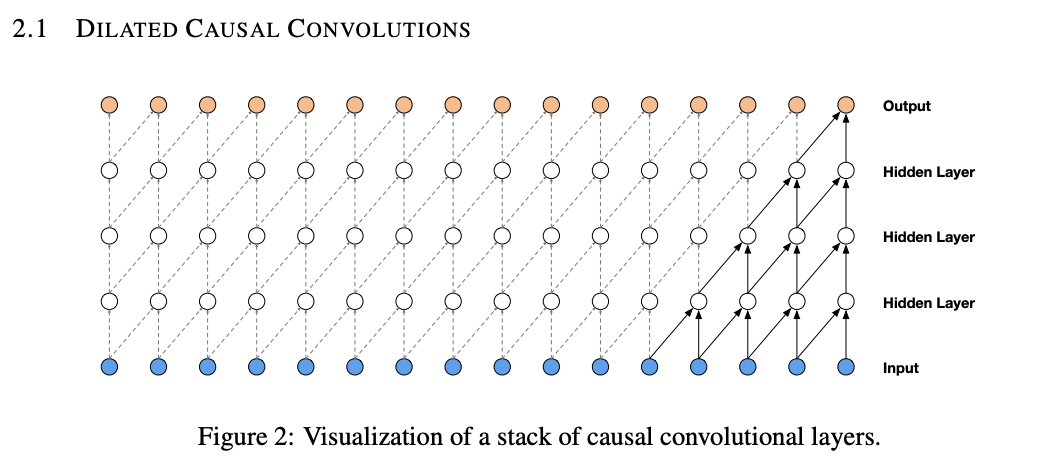
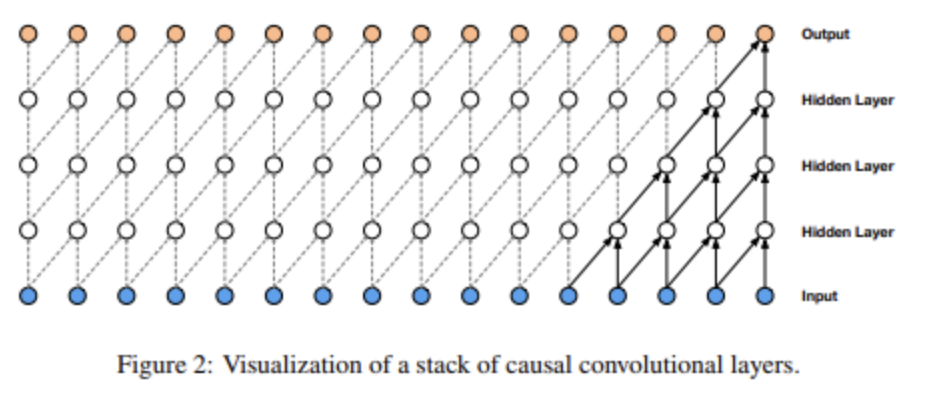
wavenet의 주요 구성 요소 = 인과적 합성곱 (causal convolution layers)
인과적 합성곱을 사용해 시계열 데이터의 모델링 순서를 모델이 위반하지 않도록 지정함
모델이 t 시간에 내놓는 예측은 figure2에서 보이는 것처럼 t+1, t+2 등 미래 시간 단계에 의존할 수 없음
위 이미지의 경우 인과적 합성곱의 대응물은 masked convolution
마스크 텐서를 구성하고 이를 적용하기 전에 합성곱 커널과 요소별 곱을 수행해 구현
오디오와 같은 1-D 데이터는 출력을 몇 개 시간 단계로 이동함으로써 더 쉽게 구현 가능
훈련 시, 모든 시간 단계의 조건부 예측은 ground truth x의 모든 시간 단계를 알기 때문에 parrallel로 진행 가능
모델 생성 시 예측은 순차적이며 각 샘플이 예측된 후, 다음 샘플 예측을 위해 네트워크로 다시 입력됨
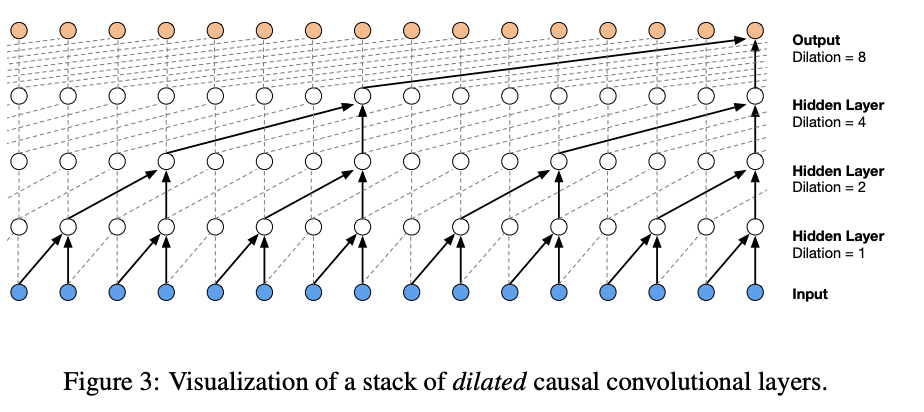
인과적 합성곱을 가진 모델은 재귀적 연결이 없어 긴 시퀀스 적용 시 더 빠른 학습이 가능 (특히 RNN보다)
인과적 합성곱의 문제 중 하나는 reception field 증가를 위해 많은 레이어 or 큰 필터가 필요함
이 문제 해결을 위해 wavenet은 계산 비용을 증가시키지 않으면서도 수용 필드를 몇 배로 증가시키기 위한 확장된 합성곱을 사용함
dilated causal convolution layer는 특정 단계로 입력값을 건너뛰면서 필터 길이보다 더 큰 영역에 적용되는 합성곱
풀링, 스트라이드 합성곱과 유사하지만 위 합성곱은 출력이 입력과 동일한 크기를 가짐
스택된 dilated causal convolution layer는 몇 개 레이어만으로 네트워크가 매우 큰 수용 필드를 가질 수 있도록 해주면서도
네트워크 전반의 입력 해상도를 보존하고 계산 효율성을 유지함
1,2,4,,,512 block은 1024 크기 수용 필드를 가지며 1*1024 합성곱의 효율적이며 비선형적인 대안이 됨
즉 확장된 인과적 합성곱은 깊이 있는 학습 모델에서 입력 데이터 특징을 더 넓은 범위에서 잡아내도록 설계된 구조
이로 인해 모델은 더 복잡한 패턴과 상관관계를 학습할 수 있으며 특히 오디오 처리, 이미지 분석 등 분야에서 강력한 성능을 발휘할 수 있음
2) softmax
일반적으로 개별 오디오 샘플 조건부 분포 모델링 방법은 혼합 밀도 네트워크(mixture density network) 또는 가우시안 스케일 혼합물 (mixture of conditional gaussian scale mixtures : MCGSM)
그러나 데이터가 암묵적으로 연속적일 때조차도 소프트맥스 분포가 더 잘 작동한다 : van den Oord et al. (2016a)
bc 범주형 분포가 임의 분포를 더 쉽게 모델링할 수 있도록 해줌, 그 형태에 대한 가정이 없어 더 유연함
raw audio는 일반적으로 16비트 정수 값의 시퀀스로 저장됨
then, 소프트맥스 레이어는 모든 가능한 값을 모델링하기 위해 타임스텝마다 65,536개 확률 출력해야함
이를 더 쉽게 하기 위해 데이터를 256가지 가능한 값으로 양자화 적용
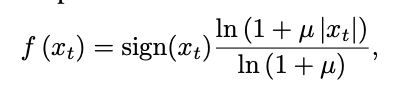
이 비선형 양자화는 단순한 선형 양자화 체계보다 훨씬 나은 재구성 제공
특히 음성의 경우, 양자화 후 재구성된 신호가 원본과 매우 유사하게 들림
3) 게이트 활성화 유닛
게이트된 PixelCNN에서 사용된 것과 동일한 게이트 활성화 유닛 사용
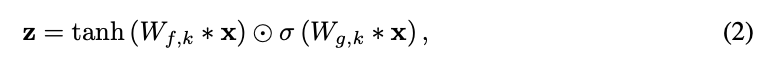
이전 초기 실험에서 ReLU 활성화 함수보다 본 비선형 함수가 훨씬 잘 작동했음
4)residual and skip connections

네트워크 전반에 걸쳐 residual connection과 매개변수화된 skip connection이 사용됨
이는 수렴 속도를 높이며 더 깊은 모델 훈련을 가능하게 함
5) conditional wavenet
추가 입력 h가 주어지면 오디오 조건부 분포 P(x|h) 모델링 가능

모델에 다른 입력 변수를 조건으로 적용하여, 원하는 특성을 가진 오디오 생성 유도
ex) 멀티 스피커 설정 시 스피커 신원을 모델에 추가 입력으로 제공하여 스피커 선택 가능
마찬가지로 TTS에는 텍스트에 대한 정보 추가 입력 필요
global conditioning / local conditioning 두가지 방식으로 모델의 조건을 조절할 수 있음
전역 조건은 하나의 숨겨진 표현 h가 모든 시간 단계에 걸쳐 출력 분포에 영향을 미치는 것이 특징임

local conditioning에서는 두번째 시계열 ht을 먼저 변환해 오디오 신호와 같은 해상도를 가진 새로운 시계열 y=f(h)로 매핑하는 transposed convolutional network 적용한 후 이 값을 활성화 함수에 적용함
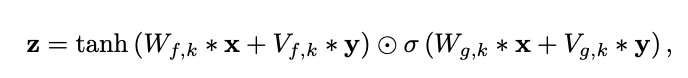
6) context stacks
receptive field의 크기를 늘리는 여러 방법들 존재 : increasing the number of dilation stages
using more layers
larger filters
greater dilation factors
a combination there of
context stack : 오디오 신호의 긴 부분 처리, 주 wavenet 모델의 context 제공하는 별도의 작은 네트워크
=> context를 사용해 주 wavenet은 오디오의 더 작은 부분만 처리하면 됨
다양한 길이와 숨겨진 단위의 수를 가진 여러 컨텍스트 스택 사용 가능
ex) 더 큰 수용 필드를 가진 컨텍스트 스택은 layer 당 더 적은 단위를 가질 수 있음
계산 부하 관리를 위해 이러한 context stack은 낮은 주파수에서 작동하는 pooling layer가 포함될 수 있음
이러한 접근 방식으로 더 긴 시간 척도에서의 시간적 상관관계 모델링하는데 더 적은 상세 정보(:적은 계산 용량)가 필요함
=> 즉, 큰 컨텍스트 처리하면서도 계산 비용 절감함 //효율, 실용성
실험
- 멀티스피커 음성 생성 : 텍스트에 따른 조건
- 텍스트 - 음성 변환 : TTS
- 음악 오디오 모델링
위 세가지 작업에 걸쳐 실험 수행
1번째 실험 : 멀티 스피커 음성 생성
- 텍스트에 기반하지 않은 자유 형태 음성 생성
- CSTR 음성 클로닝 툴킷의 영어 멀티 스피커 코퍼스 사용
- wavenet을 스키커에만 조건 적용하여 모델링
- 조건 적용 = 스피커ID를 원-핫 벡터 형태로 모델에 입력해 이루어짐
데이터셋 = 109명 다른 스피커들로부터 온 44시간 분량 데이터로 구성
모델이 텍스트에 조건화되지 않기에 실제 존재하진 않지만 인간의 언어처럼 들리는 단어들을 부드럽게 생성하며 현실감있는 억양을 가짐
이는 언어나 이미지 생성 모델과 유사
샘플들은 첫 눈엔 현실적으로 보이지만 자세히 보면 자연스럽지 X
장거리 일관성 부족은 모델의 수용 필드 크기가 제한적이기 때문 (약 300밀리초)
이는 모델이 마지막으로 생성한 2-3개 음소만을 기억할 수 있음을 의미
단일 wavenet은 스피커의 원-핫 인코딩에 조건을 적용함으로써, 데이터셋의 어떤 스피커 음성도 모델링 할 수 있음
이는 단일 모델 안에서 데이터셋의 모든 109명 스피커 특성을 포착하기에 충분히 강력함을 의미
여러 스피커 추가 = 단일 스피커만을 훈련시키는 것보다 검증 세트에서 더 나은 성능을 보임을 관찰함
이는 wavenet의 내부 표현이 여러 스피커들 사이에서 공유되고 있음을 시사함
더불어 모델이 목소리 자체 외 다른 특성들도 포착하고 있음을 관찰함
ex) 스피커의 호흡, 입의 움직임, 음향, 녹음품질도 모방
2번째 실험 : TTS
google의 북미 영어 및 만다린 중국어 TTS 시스템 구축에 사용된 것과 동일한 단일 스피커 음성 DB tkdyd
북미 영어 데이터셋 = 24.6시간 분량의 여성 음성 데이터셋
만다린 중국어 데이터셋 = 34.8시간 분량의 여성 음성 데이터셋
TTS 작업을 위한 wavenet은 입력 텍스트에서 파생된 언어적 특성에 기반해 지역적으로 조건 적용하여 학습됨
더불어 언어적 특성에 추가해 기본 주파수 값(log F0)에 조건을 적용한 wavenet도 훈련
각 언어에 대해 언어적 특성에서 log F0값과 음소(phoneme) 지속 시간 예측하는 외부 모델도 학습됨
wavenet의 수용 필드 크기는 240ms
예시 기반 및 모델 기반 음성 합성 베이스라인으로는 숨겨진 마르코프 모델 (HMM)-주도 단위 선택 연결과 장단기 기억 기반 통계 매개변수 음성 합성기 구축됨
동일한 데이터셋과 언어적 특성이 베이스라인과 wavenet 모두의 훈련에 사용되었기 때문에 이 음성 합성기들은 공정한 비교 가능
wavenet의 TTS 작업 성능 평가를 위해 주관적 짝 비교 테스트와 평균 의견 점수(MOS) 테스트 실시됨
짝 비교 테스트에서는 청취자들이 각 샘플 쌍을 듣고 가서 어느 것을 더 선호하는지 선택하라는 요청을 받음
선호도가 없는 경우 중립 선택 가능
: 5점 척도 리커트 척도(1: 나쁨, 2: 불량, 3: 보통, 4: 좋음, 5: 매우 좋음)에서 자극의 자연스러움을 평가하도록 요청

-LSTM(장단기 기억) RNN vs concat HMM(은닉 마르코프 모델)
영어의 경우 concat HMM의 선호도가 가장 높음
만다린 중국어의 경우 LSTM이 가장 많지만 못 고른 사람도 33.8%
- wavenet(L) 버전 vs wavenet(L+F)
영어의 경우 선호도를 못 고른 사람이 44%, 그나마 wavenet(L+F) 버전이 37.9%
만다린 중국어의 경우도 못 고른 사람이 64.5%였음
- baseline 모델 vs wavenet(L+F)
북미 영어의 경우 wavenet이 가장 높았고
만다린 중국어의 경우 선호도를 못 고른 사람이 58%, 그 다음이 wavenet으로 29%
wavenet은 두 언어 모두에서 베이스라인 통계 매개변수 및 연결 음성 합성기보다 뛰어난 성능을 보임
언어적 특성에 조건을 적용한 wavenet이 자연스러운 구간 품질의 음성 샘플을 합성할 수 있음
3번째 실험 : music
- MagnaTagATune 데이터셋: 이 데이터셋은 대략 200시간 분량의 음악을 포함하고 있으며, 각 29초 길이의 클립마다 188개의 태그 세트 중에서 분류된 태그들로 주석이 달려 있습니다. 이 태그들은 장르, 악기, 템포, 볼륨 및 음악의 분위기를 기술합니다.
- YouTube 피아노 데이터셋: 이 데이터셋은 YouTube 비디오에서 얻은 약 60시간 분량의 솔로 피아노 음악을 포함하고 있습니다. 단일 악기로 제한되기 때문에 모델링하기가 훨씬 쉽습니다.
수 초에 걸친 수용 범위를 가진 모델들조차 장기적 일관성을 유지하지 못해 장르, 악기 사용, 볼륨, 소리 품질이 초 단위로 변화하는 결과를 낳았음에도 불구하고 샘플들은 종종 조화롭고 미적으로 만족스러웠음 => 조건없는 모델에서 생성이 되었는데도
더불어 조건부 음악 모델들인데 장르나 악기와 같은 태크 세트를 주어진 상태에서 음악 생성 가능
'DL 기본개념' 카테고리의 다른 글
| Deep Learning : ANN, DNN, RNN, CNN (SLP, MLP) (1) | 2024.03.07 |
|---|---|
| Bayes' theorem & VAE (2) | 2024.03.01 |
| Object Detection 개념 정리 및 학습일지 (0) | 2023.10.27 |
| CV Task (0) | 2023.10.09 |
| [RNN, LSTM, GRU] (3) | 2023.10.02 |


