WaveNet : A Generative Model for Raw Audio, DeepMind
딥러닝 기반 음성합성방법 등장 전 음성 생성, 합성 방법
1. concatenative TTS 방식 : 다량의 음성 데이터를 음소로 분리,조합하여 새로운 음성 생성
2. parametric TTS 방식 : 은닉 마르코프 모델 기반 음성 합성 방식, 즉 통계적 모델 활용
but, 위 방법들은 음편 사이 경계가 매끄럽지 않아 자연스럽지 X
2016, DeepMind, 딥러닝 기반 음성 생성 모델 WaveNet 공개
- 자연스러운 음성 파형 생성
- 긴 음성 파형 학습, 생성할 수 있는 새로운 구조 제시
- 학습된 모델은 컨디션 모델링으로 인해 다양한 특징적 음성 생성 가능
- 음악을 포함한 다양한 음성 생성 분야에서도 좋은 성능을 보임

1. 모델링
T개배열로 구성된 음성 데이터 열로 음성으로써 성립할 확률 P를 학습하여 이후 생성에 활용함
t시점 기준 과거 음성 데이터 X1, ... Xt-1, Xt를 통해 Xt+1 확률 계산
Input & Output
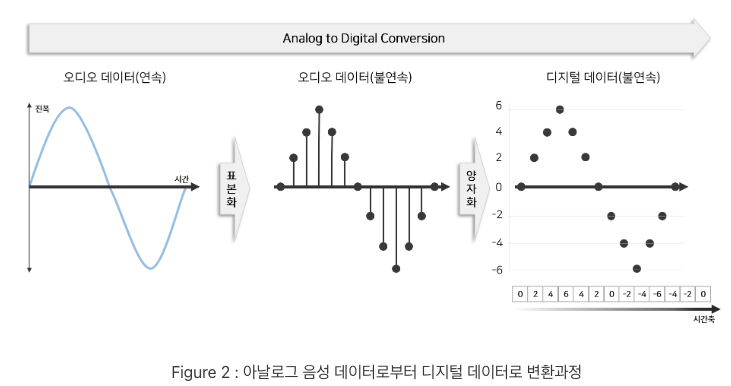
연속형 데이터인 아날로그 데이터를 컴퓨터에서 저장, 처리하기 위해 analog digital conversion을 통해 디지털 데이터로 변환
=> sampling, quantizing
즉, 음성 데이터를 이산형 디지털 데이터로 변환, 정수 배열로 표현
일반적 음성 데이터는 각 샘플을 16 bit 정수값으로 저장 => analog digital conversion을 통해 -2^15 ~ 2^15+1 사이 정수 배열로 생성
wavenet은 확률론적 모델링으로 매 t 시점 특정 파형이 나올 P를 계산 : categorical distribution으로 수월하게 가정하기 위해 256개 확률로 변환하는 mu-law companding 변환방법 사용 (-127 ~ +128)
Dilated Causal Convolutions
: 모델의 과거 음성 정보에 접근
: dilated convolution layer + causal convolution layer
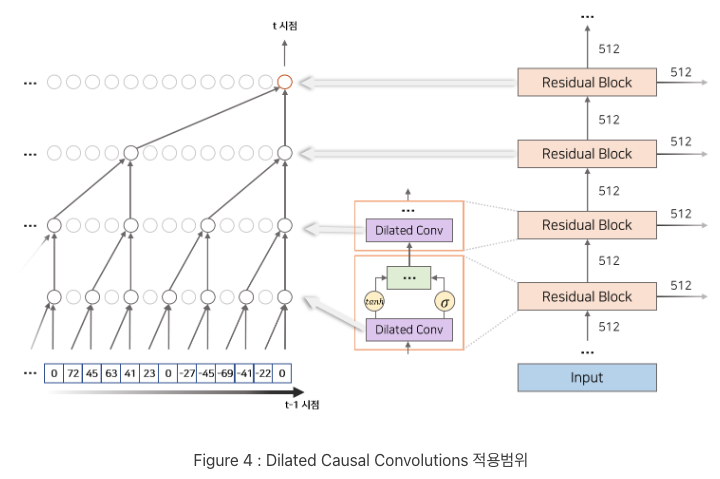
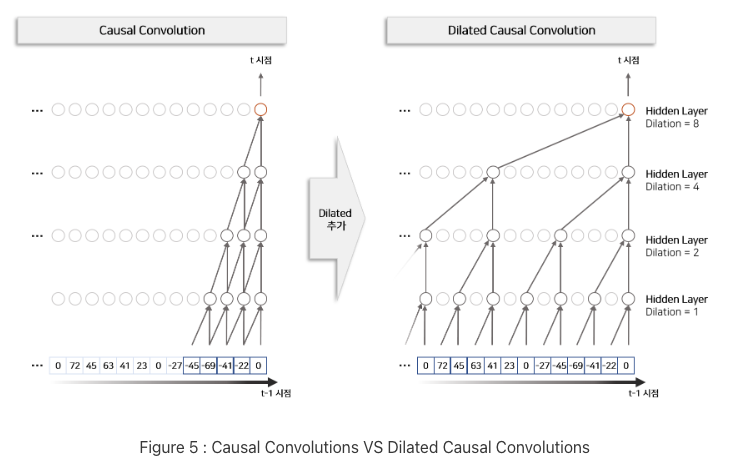
- dilated convolution
추출 간격 조정하여 더 넓은 receptive field 추출하면서도 계산량을 늘리지 않음
더 적은 layer를 쌓아도 더 넓은 수용 범위 도출 가능
- causal convolution
시간 순서 고려하여 convolution filter 적용
causal convolution을 위로 쌓을수록 input 데이터의 수용범위가 커짐
RNN 모델처럼 음성 데이터, 즉 시계열 데이터 모델링 가능

하나의 residual block은 하나의 dilated conv와 2개의 일반 conv, activation function(tanh, sigmoid), 1*1 conv로 구성됨
dilated conv로 생성된 벡터는 conv+tanh 경로 / conv+sigmoid 경로, 2개의 경로를 통해 계산됨
각 경로로 계산된 벡터는 다시 element-wise 곱을 통해 하나의 벡터로 변환되며 이 방식을 gated activation units이라고 함
gated activation units
각 layer에서 생성한 지역적 특징 = filter
위 필터 정보를 다음 layer에 얼만큼 전달해줄지 정하는 수도꼭지 역할을 함
gated activation unit을 통해 생성된 벡터 z는 1*1 conv layer를 지나 residual connection으로 해당 layer inputrhk 합쳐서 layer output이 됨
위 residual connection 구조는 딥러닝 모델을 더 깊게 쌓게 할 뿐만 아니라 빠르게 학습할 수 있도록 도움
skip connection

skip connection은 각 residual block layer에서 생성된 layer outputdmf 1*1 conv를 통해 합하는 과정으로 구현됨
각 residual block layer에서 생성된 output은 later depth에 따라 서로 다른 수용범위를 이용하여 local output을 생성함
위 정보들을 모두 합해 최종 모델의 output을 생성함
conditional wavenet
wavenet에 조건에 맞는 각 특징들을 추가하여 모델학습 가능
- global conditioning : 시점에 따라 변하지 않는 조건 정보 추가
- local conditioning : 시점에 따라 변하는 조건 정보 추가
global conditioning
ex) 모델로부터 여러 화자의 음성 생성 시 화자 정보 h를 추가해 음성과 함께 학습
위 정보는 화자 고유 특성이지 시점별로 변하는 정보가 아님
그렇기 때문에 전역적 조건정보 h를 모든 시점에 동일하게 추가하여 모델 학습 및 생성에 영향 부여
local conditioning
ex) TTS인 경우 linduistic feature or text embedding 과 같은 정보를 추가하여 음성 생성
위 정보는 음성과 길이는 다르지만 순서가 있는 일정 길이의 sequence 벡터
따라서 위 조건 정보를 음성 정보와 매칭시켜 시점에 따라 다르게 넣어주어야함
즉, '나는 사과를 좋아한다' text를 조건 정보로 추가 시 음성에서 '사과'라는 소리가 나오는 시점에 '사과' 단어의 embedding이 영향을 주도록 음성과 조건 정보 시점 매칭해야함
'Paper Review > Generative models' 카테고리의 다른 글
| [Paper Review] WAVENET: A GENERATIVE MODEL FOR RAW AUDIO, 2016 arXiv (3) | 2024.11.01 |
|---|---|
| [Paper Review] Inpaint-Anything, 2023 CVPR (6) | 2024.10.25 |
| Generative Adversarial Nets : GAN (4) | 2024.09.16 |
| [Paper Review] RePaint: Inpainting using Denoising Diffusion Probabilistic Models (0) | 2024.02.12 |
| Palette: Image-to-Image Diffusion Models (0) | 2024.02.04 |


