💡 현대 이미지 인페인팅 시스템의 한계 : mask selecting, hole filling
따라서 SAM을 기반으로 하여 마스크가 필요 없는 이미지 인페인팅의 첫 시도
→ clicking and filling : IA
- Remove Anything
- Fill Anything
- Replace Anything
https://github.com/geekyutao/Inpaint-Anything
목차
Why do we need Inpaint Anything?
Motivation & observation
Why do we need Inpaint Anything?
최신 이미지 인페인팅 SOTA : LaMa, Repaint, MAT, SITS
넓은 영역을 성공정으로 인페인팅할 수 있음
복잡한 반복 구조에도 잘 작동하며 고해상도 이미지에 좋은 일반화성능을 가짐
But, 세밀한 annotation이 필요함
SAM : point, box 등의 prompt를 사용해 고품질 object mask 생성
이미지 내 모든 객체에 대한 포괄적, 정확한 마스크 생성
But, 이러한 마스크가 실제 인페인팅 작업에서 어떻게 더 다양하게 활용될 수 있는지에 대한 연구 부족
기존의 인페인팅 방법은 제거된 영역을 주변의 맥락으로만 채울 수 있었다
But, AIGC: al 생성 콘텐츠는 창작의 새로운 기회를 열어주어 사람들이 원하는 새로운 contents를 생성하는데 도움을 줄 수 있다
⇒ SAM, 최신 이미지 인페인팅 기술들, AIGC 모델의 장점을 결합하여 객체 제거, new contents 채우기, 배경 교체 등과 같은 일반적 인페인팅 문제를 해결할 수 있는 pipeline 제공
Inpaint Anything 모델은 SAM의 뛰어난 마스크 생성 기능, 최신 인페인팅 기술들의 정교한 이미지 보완 능력, 그리고 AIGC 모델의 텍스트 프롬프트 기반 생성 및 다양한 조건(컨디션)을 부여할 수 있는 멀티모달 기능을 결합한 모델
What Inpaint Anything can do?
SAM + SOTA Inpainters(LaMa) for removing anything
- SAM을 통해 생성된 마스크를 사용해 경계를 부드럽게 수정한 후 인페인팅 모델에 입력으로 제공, 이를 명확히 제거할 객체 영역 지정 후 채우는 작업 수행
- Inpaint Anything을 통해 인터페이스에서 특정 객체를 클릭하여 쉽게 제거 가능하며 결과로 생긴 hole을 주변 맥락 데이터로 채울 수도 있음
SAM + AIGC models for filling or replacing anything
- hole을 주변 데이터 혹은 새로운 콘텐츠로 채울 수 있는 옵션 제공
- ex) stable diffusion을 사용해 text prompt로 새로운 객체 생성 가능
- IA를 사용해 클릭한 객체를 제외한 나머지 배경을 새로운 장면으로 대체할 수 있음
- hole을 주변 데이터 혹은 새로운 콘텐츠로 채울 수 있는 옵션 제공
Methodology
Preliminary
Segment anything
- 다양한 상황에서 뛰어난 segmentation 능력 보유
- foundation model
- 대규모 시각 데이터:SA-1B를 바탕으로 훈련된 ViT 기반의 대형 모델
Sota Inpainters
- 이미지 인페인팅 : 손상된 이미지의 결여된 영역을 시각적으로 자연스러운 구조와 텍스처로 대체
- 인페인팅 전략 / 네트워크 구조 / 손실함수 등..
- LaMa, perceptual loss, aggressive training mask generation strategy
- LaMa (fast fourier convolutions : FFCs)를 사용해 마스크 기반 인페인팅 적용
AIGC
- Artificial Intelligence Generated Content
- ai 모델을 통해 디지털 콘텐츠 생성하는 기술로 다양한 콘텐츠 생성 작업에서 최첨단 성능을 보여줌
Inpaint Anything
Remove Anything
- 객체 제거에 초점
- 이미지에서 특정 객체를 클릭하여 제거하며 결과 이미지가 시각적으로 자연스럽도록 함
- 사용자 제거 객체 클릭
- SAM을 사용해 객체 자동 분할 및 마스크 생성
- LaMa를 사용해 객체의 빈 공간을 주변 정보를 사용해 채움
Fill Anything
- 사용자가 원하는 콘텐츠로 이미지 내 객체 채움
- 객체 클릭
- remove anything과 동일한 방법으로 객체 분할
- 사용자가 원하는 내용의 텍스트 프롬포트 제공
- stable diffusion을 사용해 text를 마탕으로 객체 영역 fill
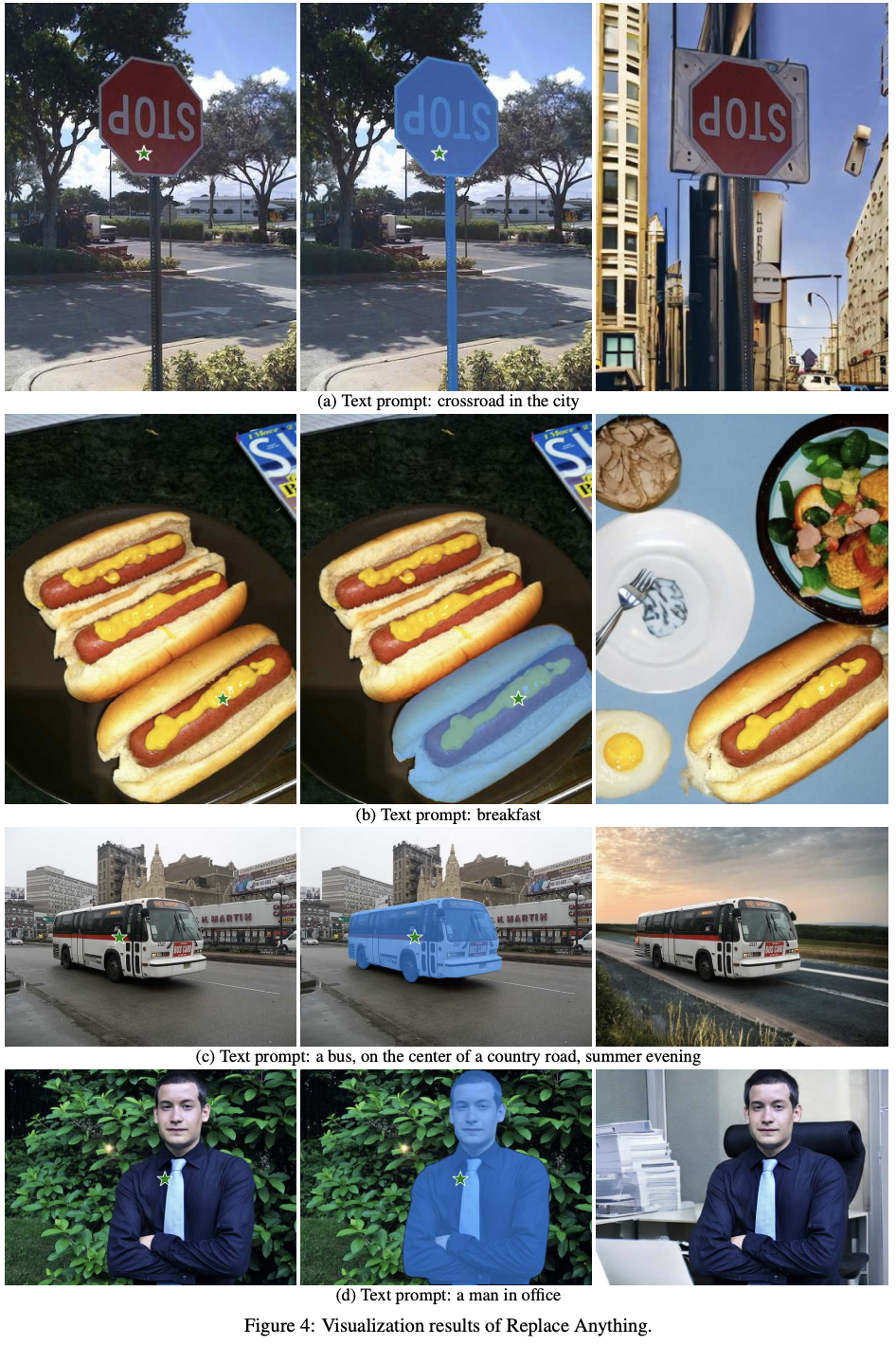
Replace Anything
- fill anything과 유사한 프로세스를 따르지만, 이 경우 생성되는 새로운 배경은 객체 외부의 기존 배경과 일관된 배경을 생성하도록 프롬포트를 받음 (새로운 재구성이라고 보면 될 듯)
- 객체 대신 다른 배경으로 대체하는 기능
Practice
기초 모델의 조합과정에서의 호환성 문제 해결을 위한 모델과 task 간의 중간 처리 과정
Dilation matters
- SAM이 생성한 segmentation 결과 중 종종 비연속적이거나 매끄럽지 않은 부분 혹은 객체 내부의 hole이 포함된 경우가 있음
- mask dilation을 통해 마스크 경계 개선
- 특히나 fill anything에서는 넓은 마스크가 AIGC가 표현할 수 있는 더 많은 공간을 제공하므로 의도에 부합하는 결과를 얻기 위해 넓은 dilation을 적용함
Fidelity matters
- 일반적으로 최신 AIGC 모델은 고정된 해상도를 요구 ex) 512*512
- 하지만 단순히 이 해상도로 진행하게 되면 충실도:fidelity가 떨어져 최종 결과에 부정적인 영향을 끼칠 수 있음
- → cropping / resizing 시 원본의 종횡비를 유지하는 방법 필요
Prompt matters
- 텍스트 프롬포트는 AIGC 모델 결과에 상당한 영향을 미친다
- 간단한 프롬포트(간결, 구체)의 성능이 더 좋다
- ex) "벤치에 있는 곰 인형", "벽에 걸린 피카소 그림”
Experience
IA의 세가지 기능 평가
- COCO 데이터셋, LaMa test set, 직접 촬영한 사진
다양한 콘텐츠, 해상도, 종횡비 이미지를 효과적으로 인페인팅 할 수 있음


Conclusion
IA는 remove anything, fill anything, replace anything의 기능을 통해 마스크 없이도 인페인팅을 수행할 수 있으며
click 후 제거 / 프롬포트로 채우는 등 사용자 친화적인 작업 방식을 제공함
더불어 다양한 종횡비와 2K 해상도를 포함하여 고품질의 입력 이미지를 처리할 수 있음
⇒ 대형 AI 모델의 잠재력을 완전히 활용하여 강력한 기능을 발휘
⇒ composble AI:조합 가능한 AI의 가능성을 제시
'Paper Review > Generative models' 카테고리의 다른 글
| [Paper Review] WAVENET: A GENERATIVE MODEL FOR RAW AUDIO, 2016 arXiv (2) | 2024.11.01 |
|---|---|
| Generative Adversarial Nets : GAN (1) | 2024.09.16 |
| [Paper Review] RePaint: Inpainting using Denoising Diffusion Probabilistic Models (0) | 2024.02.12 |
| Palette: Image-to-Image Diffusion Models (0) | 2024.02.04 |
| WaveNet : A Generative Model for Raw Audio (DeepMind) (0) | 2023.11.22 |


