기존 RNN 모델은 vanishing gradient와 long-term dependency를 해결하지 못하였다.
따라서 이를 해결하기 위해 attention을 도입하여 중요한 정보에 가중을 두고 학습할 수 있도록 하여 long-term dependency를 해결했다.
하지만 여전히 순차적 계산으로 인해 병렬화가 불가능했으며, long-term dependency와 encoder가 뽑은 표현에 의존하는 구조가 문제
따라서 Transformer 등장
| 기존 | 해결책 |
| RNN은 단어를 순차적으로 처리하는 과정에서 hidden state 하나로 전체 문맥을 압축 -> 정보 손실 | self-attention을 통해 각 단어가 전체 시퀀스를 바라보며 각 단어의 의미를 벡터로 인코딩함 -> 풍부한 표현 |
| 장기 의존성과 함께 cnn 기반 모델은 고정된 윈도우로 인해 긴 문장을 제대로 학습하지 못함 | self-attention으로 모든 위치 간 관계를 직접 계산하여 먼 거리 관계도 쉽게 반영하며 positional encoding으로 순서 정보를 삽입 |
| time-step 순차적 계산 | 모든 입력을 한 번에 처리하여 병렬 연산 가능 |
Transformer : Encoder-Decoder 구조

간단한 Attention 짚고 넘어가기
4차원 세계(x, y, z, 시간)은 대부분의 데이터가 시계열 형태이다.
시계열 데이터는 여러 개의 연속된 데이터 포인트를 의미있게 풀어내야한다.
즉, 복잡한 데이터를 하나의 의미 있는 벡터로 표현할 필요가 있다.
기존의 RNN은 데이터를 한 시점씩 순차적으로 처리한다.
첫 번째 단어 -> 두 번째 단어 -> ...
따라서 병렬화가 안되고 뒤로 갈수록 흐릿해지는 문제가 존재한다.
"모든 시점의 데이터를 동시에 보고, 어떤 부분이 중요한 부분을 계산하자"
HOW?
모든 데이터 포인트를 서로 비교해 score 계산
중요도만큼 정보를 더 반영하여 전체 문장을 요약한 벡터를 만듦
트랜스포머는 이러한 Attention을 사용하여 다중의 데이터 포인트를 효과적으로 반영하고, 장기 의존성을 처리하였다!
Transformer : Multi-Head Attention
하나의 어텐션만 사용하기보다 여러 개 헤드의 어텐션을 사용하면 더 풍부한 정보 파악이 가능해진다.
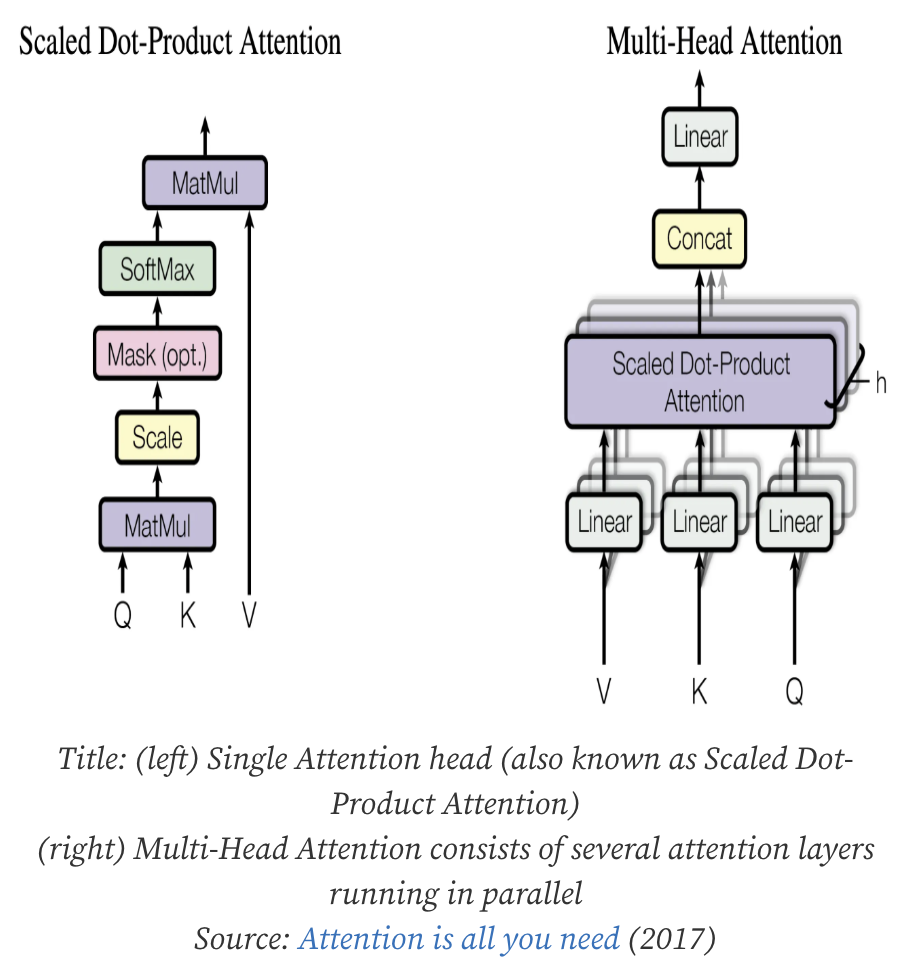
HOW?
입력 벡터를 여러 세트로 분리하여 각 세트(헤드)를 독립적으로 Self-Attention을 수행한다.
서로 다른 weight matrix로 Query, Key, Value를 생성
모든 head의 결과를 concat하고 다시 한 번 선형 변환하여 최종 output을 생성한다.
이를 통해 서로 다른 위치 관계, 의미관계, 구분적 패턴을 동시에 학습한다.
이렇게 병렬적인 시각을 통해 전체적 문맥을 풍부하게 파악할 수 있다.
+ scaled Dot-Product Attention
Query, key의 벡터 유사도를 계산하고 그에 따라 Value 벡터를 가중합하여 중요한 정보를 추출하는 과정
- Q와 모든 K 사이의 관계 계산 -> 얼마나 중요한지
- 차원이 커질수록 내적값이 커지기 때문에 scale 조절한후 softmax 적용 = 가중치 확보
- V에 가중합 적용
=> 즉, 입력 벡터를 여러 조각으로 나누어 각 조각별로 self-attention을 수행하며 독립적으로 scaled dot product attention을 수행
=> 각 head의 출력을 concat한 후 최종 linear layer 적용
Transformer : Self-Attention
문장 속 단어들이 서로 어떤 영향을 주는지 계산하고 각 단어의 표현에 해당 정보를 녹여 넣는다.
HOW?
입력 단어인 각 토큰을 3개의 벡터로 바꾼다.
Query, Key, Value -> (Wq, Wk, Wv)
이를 특정 단어의 Q와 다른 단어들의 K를 dot product하여 얼마나 관련있는지 유사도를 계산
이를 가중합하여 출력 벡터를 생성한다.
Self-Attention (단일) = Scaled Dot-Product Attention (1개)
Multi-Head Attention = 여러 개의 Scaled Dot-Product Attention + 합치기(Concat + Linear)
Transformer : Cross-Attention
트랜스포머의 디코더에서 사용되며 번역이나 요약처럼 입력시퀀스를 보고 새로운 시퀀스를 생성할 때 필수이다.
인코더가 이해한 문맥을 참조하여 디코더가 다음 단어를 더 정확하게 생성할 수 있도록 도와줌

HOW?
인코더 입력 : 나는 학교에 간다 (한국어 -> 인코더)
디코더 입력 : I go (지금까지 생성된 것)
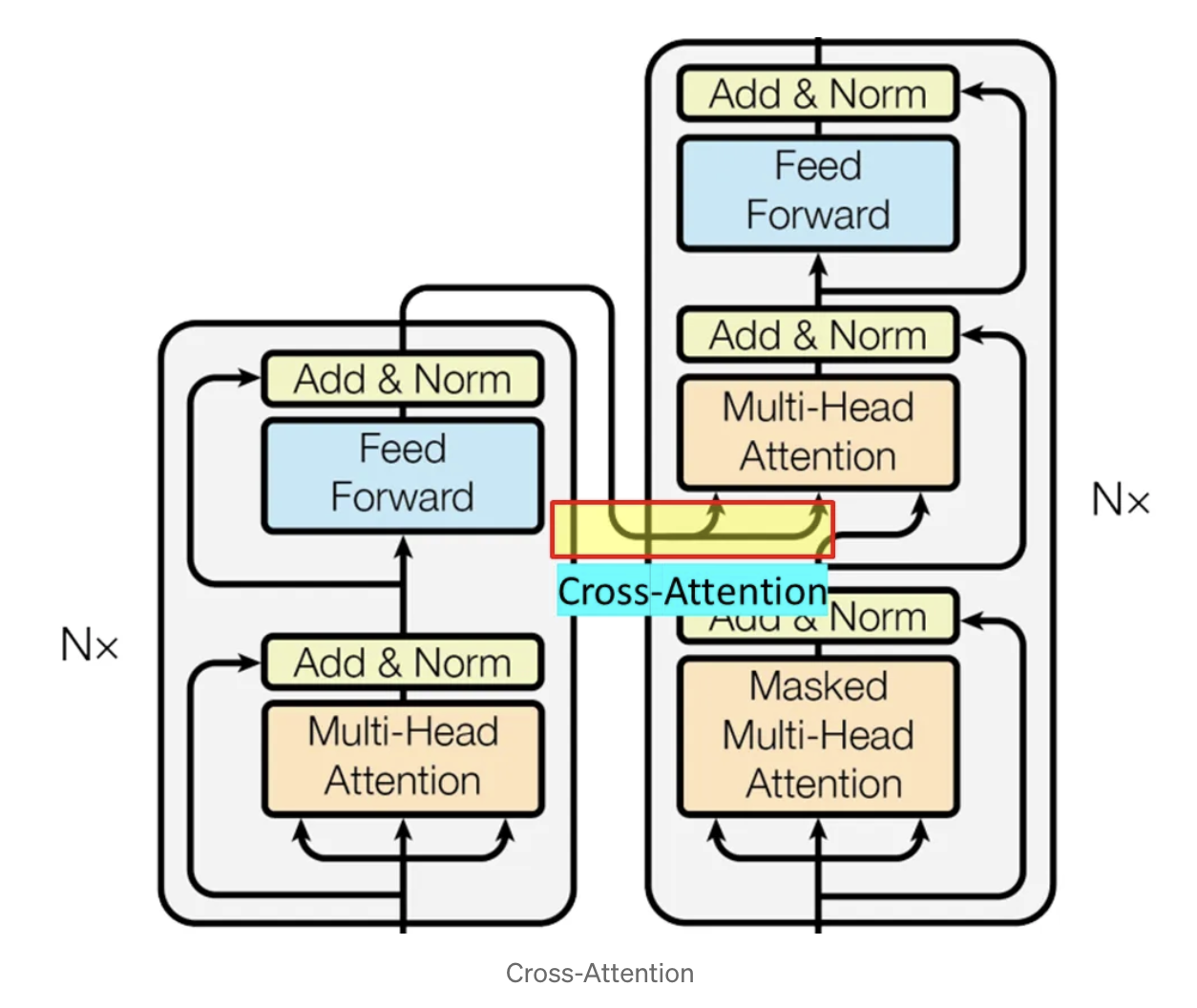
인코더는 입력 문장을 각 벡터로 변환한다. 이때 인코더의 전체 출력이 K, W 각각의의 가중합로 변환되어 Cross-Attention에 저장됨
디코더는 현재까지 생성된 단어를 이용해서 Query를 생성한다.
(go -> query vector)
Q와 모든 K 사이의 유사도를 계산한다. Attention scorei = q*ki
유사도를 확률처럼 바뀍 위해 softmax를 사용한다.
(나는=0.1, 학교에=0.3, 간다=0.6)
V 벡터들에게 가중합하여 최종 컨텍스트 벡터를 생성한다.
(간다가 0.6으로 가장 크므로 간다를 가장 많이 보고 이 정보인 V를 반영하여 다음 단어 생성에 쓸 정보를 판단)
Transformer : Positional Encoding
Attention의 한계
어텐션은 어떤 단어가 다른 단어와 얼마나 관련이 있는가?만 계산을 한다.
이렇게 되면 시계열 데이터는 순서가 중요한 반면 이는 벡터간 위치에 고려되지 않아 "나는 학교에 간다" == "학교에 나는 간다"가 된다.
RNN은 순차적으로 처리하여 포지션을 인코딩해줄 필요가 없지만 트랜스포머는 병렬 처리기때문에 한 번에 처리되는 문장 속 단어의 순서 구분을 직접 해주어야한다! 즉, 문장 안의 상대적 위치를 직접 반영해주어야한다.
HOW?
각 위치마다 고유한 위치 벡터를 더해 모델이 이 단어가 몇 번째인지 알 수 있게 한다.
사인/코사인 함수를 사용해 서로 다른 주기를 가진 패턴을 사용하면 위치에 따라 고유한 벡터가 만들어진다.

t:시퀀스 위치, i:벡터의 차원, d:임베딩 차원 수
sin 내부 함수부터 살펴보자 : 2i/d를 보면 차원 i가 커질수록 분자가 커지게 되어 10000^큰수 = 아주 큰 수이므로 삼각함수가 느리게 변한다. 즉, 이 방법은 차원에 따라 다른 함수를 도출할 수 있는 것!
+ sin/cos은 주기적이며 서로 시작점이 다르기 때문에 짝지어 넣어 위치 t가 바뀔 때마다 벡터 전체에서 고유한 파형이 만들어진다.


=> 이렇게 최종적으로 각 단어는 자기 뜻을 담은 단어 임베딩 벡터와 위치 인코딩 벡터를 합하여 트랜스포머에서 구분되며 학습된다.
* 포지셔널 인코딩에 대해 추후 다양한 방법론이 연구되어 나왔음
Transformer : 장점
기존 RNN은 순차적으로 처리해야해 문장이 길어질수록 처리 시간도 길어지며 병렬화가 안 돼어 GPU 성능도 못 사용한다.
그렇다면 Transformer는 왜 빠른가?
입력 문장 전체가 한 번에 들어가 각 단어들이 동시에 self-attention이 수행된다.
각 단어들과 모든 다른 단어와의 관계를 계산하여 결과를 벡터로 재조합하여 인코딩을 완료한다.
시간 복잡도 O(n) => O(1)
단순한 아키텍쳐 : 간순하지만 확장 가능한 구조
트랜스포머는 딱 두 가지 기본 블록만 반복한다.
1. multi-head attention
2. position wise feed forward network
이 두 가지를 조립하여 인코더, 디코더를 만들고 필요하면 레이어 개수만 늘리면 소형 모델 ~ 대형 모델까지 확장이 가능하다.


=> 블록 하나하나가 독립적이며 교체 또는 확장이 가능하다
=> 모든 레이어가 동일한 패턴을 따른다 : 어텐션 -> 잔차 연결 -> 정규화 -> FFN -> 잔차연결 -> 정규화
=> 병렬 처리 최적화
=> 유연한 시퀀스
트랜스포머의 안정적 학습
1. Layer Normalization
딥러닝은 깊은 네트워크일수록 불안정이 더 심해진다.
하나의 레이어에서 나온 출력값 벡터 전체에 대해 평균을 빼고 분산을 나눠 정규화된 값으로 바꾼다.

이를 통해 각 레이어의 출력값이 적당한 분포로 유지된다.
빠른 수렴, 폭주 방지, 안정적 파라미터 업데이트 가능
2. Residual Connection
깊은 네트워크에서는 정보가 레이어가 지날수록 점점 흐려지거나 사라진다.
output = layer(x) + x
입력값을 그대로 출력에 더해 정보 손실을 방지하며 깊은 네트워크에도 잘 학습 가능
3. Attention Mechanism
모든 단어를 중요하게 처리하는 것이 아니라 각 단어가 다른 단어들과 얼마나 중요한 관계인지 계산하여 가중치 부여
학습 초기에 노이즈를 억제하고 유의미한 관계로부터 학습할 수 있게 도와준다. 정보의 흐름이 선택적으로 강화된다.
Transformer : Pretrained
사전학습 데이터
위키피디아, 뉴스, 책 등 거대한 텍스트 코퍼스 데이터를 사용
BERT : Masked Language Modeling -> transformer의 인코더만 사용
문장 중 일부 단어를 가리고 그 자리에 무엇이 들어갈지 맞추는 훈련
ex) 나는 [mask]에 갔다.
=> 모델이 mask에 어떤 단어가 들어가야 자연스러운지 예측해야함
=> 잘 예측하기 위해서는 문장 전체 맥락을 이해해야하고 앞 뒤, 양쪽을 동시에 고려하게 되어 양방향 문맥 이해에 강하다.
GPT : Next Token Prediction -> transformer의 디코더만 사용
문장을 앞에서부터 하나씩 읽으며 다음에 나올 단어를 예측하는 훈련
ex) 나는 학교에 ~.
=> 이전 단어만 보고 다음 단어를 예측하기 때문에 왼쪽 -> 오른쪽으로의 흐름을 이해한다.
=> 따라서 텍스트 생성에 강하다.
'DL 기본개념' 카테고리의 다른 글
| Model Context Protocol (0) | 2025.04.07 |
|---|---|
| Deep Learning : ANN, DNN, RNN, CNN (SLP, MLP) (1) | 2024.03.07 |
| Bayes' theorem & VAE (2) | 2024.03.01 |
| Wavenet 논문 전체 내용 (1) | 2023.11.01 |
| Object Detection 개념 정리 및 학습일지 (0) | 2023.10.27 |



