WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
목차
Abstract
raw audio waveforms 생성을 위한 deep neural network
- fully probabilistic
- autoregressive
⇒ 각 오디오 샘플의 예측 분포는 이전 모든 샘플에 따라 결정된다
하지만 오디오 샘플은 기본 초당 16000-48000개 # 이미지 데이터에 비해 훨씬 많은 샘플 수 존재
그럼에도 WaveNet은 초당 수만 개의 샘플을 포함하는 데이터를 효율적으로 학습할 수 있음
초기 audio generation의 SOTA
현재는 HiFi-GAN, WaveGan 등
Introduction
conditional distribution의 곱으로 픽셀이나 단어의 결합확률을 신경망 구조를 사용해 모델링하면 좋은 결과를 얻을 수 있음 : PixelCNN
→ 이는 수천개의 확률변수에 대한 분포의 모델링이 가능하다
이 방식으로 기반으로 하여 효율적인 모델링 방법을 적용한다면 이미지 데이터보다 훨씬 긴 시간적 종속성을 가지는 오디오 데이터셋 또한 매우 높은 해상도를 가진 raw audio waveform을 생성할 수 있음
효율적인 모델링 방법 : dilated causal convolutions
WaveNets

- 파형의 결합 확률은 모든 이전 시간 단계의 샘플 condition에 영향을 받음
- PixelCNNs와 유사하게 예측은 이전 픽셀들의 값들을 기반으로 현재 샘플의 확률분포를 모델링
- 네트워크에는 pooling layers가 없고 모델의 출력은 입력과 동일한 시간 차원을 가진다
- softmax layer를 사용해 다음 값 Xt에 대해 범주형 분포를 출력하며 데이터의 로그 우도를 모델의 매개변수에 대해 최대화하도록 최적화함
- 로그 우도는 계산이 가능하여 검증 세트에서 하이퍼파라미터를 조정할 수 있고 모델의 과적합 혹은 과소적합을 쉽게 측정할 수 있음
Dilated Causal Convolutions
causal convolutions
시계열 데이터는 미래 순서의 데이터를 기반으로 예측하면 안되기 때문에 데이터 모델링 순서를 위반하지 않도록 과거 데이터들만 참고하여 현재 샘플을 예측하도록(시간 t에서의 모델의 예측이 미래 시간 단계를 참조하지 못하도록) 보장
모델 학습 시) 참값을 알 수 있어 모든 시간 단계의 조건부 예측을 병렬 수행 가능
데이터 생성 시) 예측이 순차적으로 이루어지며 각 샘플이 예측될 때마다 해당 샘플이 네트워크에 다시 입력되어 다음 샘플의 예측에 사용됨
인과적 합성곱을 사용하게 되면 recurrent connection이 없어 긴 시퀀스에 적용될 때 RNN보다 빠름

인과적 합성곱을 사용하게 되면 recurrent connection이 없어 긴 시퀀스에 적용될 때 RNN보다 빠름
하지만, receptive field를 넓히기 위한 큰 필터 혹은 많은 layer가 필요함
위 문제 해결을 위해 dilated convolution 사용
Dilated Convolution
필터가 일정한 간격을 두고 입력 값을 건너뛰어 더 넓은 영역에 적용됨
pooling or stride 합성곱과 비슷하지만 출력이 입력과 동일한 크기를 갖는 것이 차이
→ 일반적인 경우 출력 크기가 점점 줄어 정보가 축소되며 입력 데이터의 해상도가 줄어들 수 있음
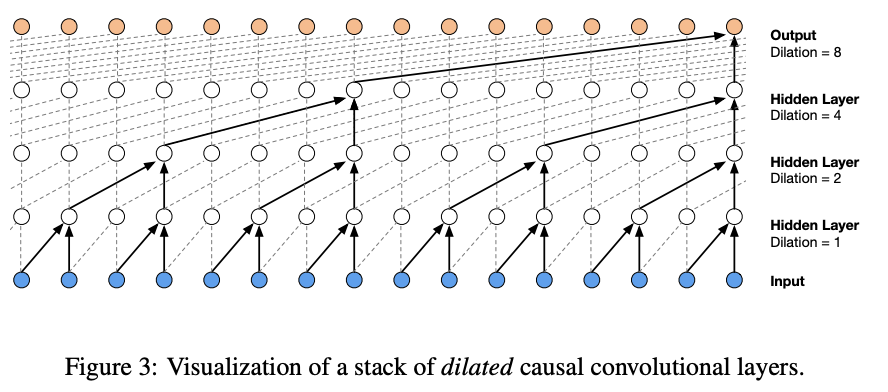
⇒ causal dilated convolution을 통해 입력의 크기를 그대로 유지하면서도
더 넓은 범위의 정보를 보다 적은 계산량을 사용하여 처리할 수 있음
Softmax distributions
개별 오디오 샘플에 대한 조건부 분포 모델링 방식 연속적인 값에 기본적으로 적용하는 mixture model 사용
- mixture density network
But, 이 경우 소프트맥스 분포가 더 잘 작동함을 알아냄
오디오 데이터가 연속적이지만 실제로는 양자화되어 이산적인 값들을 가지기 때문에 ex) 8-bix : 2^8 = 256개
연속적인 확률 분포를 가정하는 mixture model보다 이산적 분포를 기반으로 하는 모델이 더 적합!!
categorical distribution이 더 유연하며 분포의 형태에 대한 가정을 하지 않아 임의의 분포를 더 쉽게 모델링 할 수 있기 때문
가우시안 분포라고 한다면 평균,분산으로 분포의 형태를 정의할 수 있음 하지만 해당 데이터가 가우시안을 따르지 않으면 적절하지 않음
반면 범주형은 각 값에 개별 확률을 부여하여 복잡한 형태의 데이터라도 조절가능
raw audio : 일반적으로 각 시간 단계 당 하나의 값이 16비트 정수값 시퀀스로 저장됨
2^16=65536개
이를 아래 공식으로 양자화하여 256개로 만들어 적용함
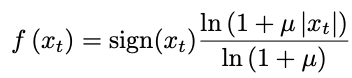
Gated Activation Units
게이트가 있는 PixelCNN 에서 사용된 것과 같은 게이트 활성화 단위를 활용함
오디오 신호를 비선형적으로 처리하여 선형 활성화 함수인 ReLU보다 더 잘 작동함을 확인함
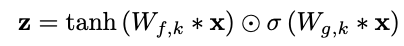
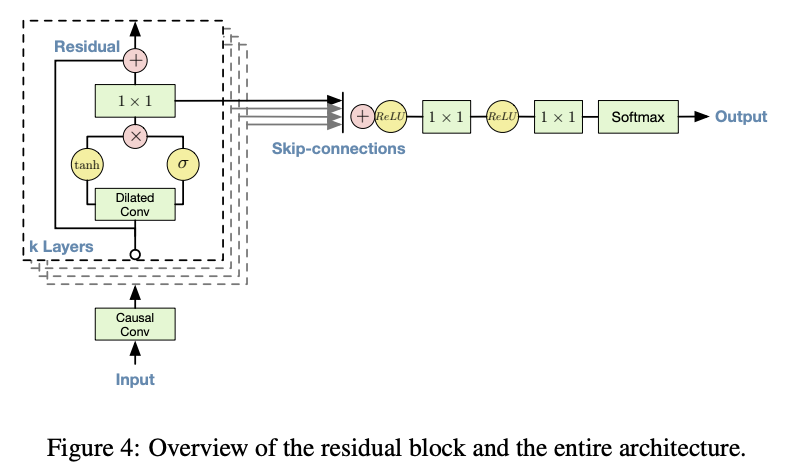
Residual and skip connections
residual connection & skip connection 사용
- residual connection
- 깊은 네트워크에서의 주요 정보 손실 방지
- 입력 신호가 각 층을 거칠 때마다 일부 정보를 직접 전달하도록 설계
- skip connection
- 네트워크의 여러 층에서 나온 정보를 모아 최종 출력에 반영하여 더 풍부한 표현을 얻음
- 중간 출력을 최종 출력과 결합하도록 해줌
Conditional Wavenets
추가 입력 h를 사용하여 오디오에 대한 조건부 분포를 모델링할 수 있다
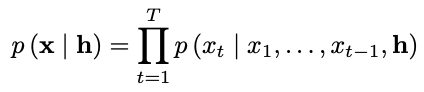
- global conditioning
- 하나의 전역적 h가 모든 시간 단계의 출력에 영향을 줌
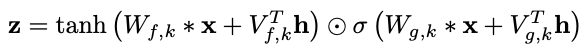
- local conditioning
- → 오디오 신호보다 낮은 샘플링 주파수를 가질 수 있음
- 시간에 따라 변화하는 두 번째 시계열 사용
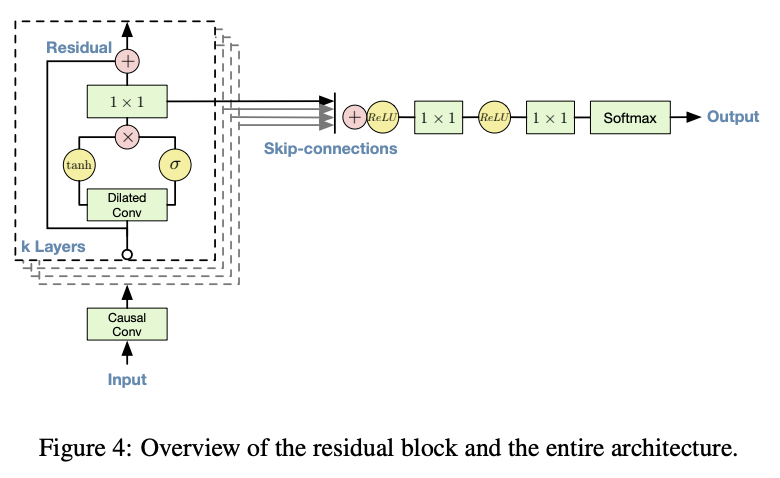
전체 FLOW
입력
→ causal convolution : 과거 값만 참조하며 데이터 예측
→ dilated caudal convolution : 더 긴 시간 의존성을 모델링 하기 위해 적용 #계산 효율성, 넓은 수용영역 확보, 수많은 층 필요 X
→ residual blocks : layer을 통과하며 손실되는 정보들을 추가해줌
→ skip connections : 각 층의 출력 정보를 최종 출력과 결합 #다양한 수준의 정보를 잘 통합
→ softmax distribution : 범주화를 통해 복잡한 데이터 적절히 표현
→ conditional wavenet : 단순한 오디오 생성 뿐 아니라 외부 조건에 맞는 오디오를 생성할 수 있음
Experiments
- 다중 화자 음성 생성
- 텍스트-음성 변환 : TTS
- 음악 오디오 모델링
다중 화자 음성 생성
자유 형식의 음성 생성 - not text
- VCTK 데이터셋을 사용
- 화자의 원-핫 인코딩에 조건화하여 데이터셋의 109명 모든 화자의 음성을 모델링할 수 있었음
→ 단일 모델로 여러 화자의 특성을 포착할 만큼 강력
TTS : 텍스트-음성 변환
북미 영어 데이터셋은 24.6시간 분량의 음성 데이터를 포함
만다린 데이터셋은 34.8시간 분량으로, 둘 다 전문 여성 화자가 녹음
- WaveNet은 입력 텍스트에서 파생된 언어적 특징에 로컬하게 조건화
- WaveNet은 기준 모델보다 더 자연스러운 음성을 생성
자연 음성과의 MOS 점수 차이가 크게 줄었음
음악 오디오 모델링
MagnaTagATune 데이터셋 : 약 200시간 분량의 음악 오디오로 구성
YouTube 피아노 데이터셋 : 약 60시간 분량의 솔로 피아노 음악
- 수용 영역을 넓히는 것이 음악적 품질에 중요
- 여전히 장기적 일관성 문제는 해결되지 않았음
Speech Recognition
본 모델은 생성 모델로 설계되었지만 음성 인식 등의 discriminative 작업에도 간단히 적용가능했음
causal convolution을 사용하여 LSTM 유닛의 사용보다 더 효율적으로 수용 영역을 확장할 수 있음을 보여주었음
Conclusion
오디오 데이터를 위한 심층 생성 모델을 소개함
autoregressive, causal dilated convolutions
→ 오디오 신호의 장기적 시간 의존성 모델링에 적절했음
condition을 전역적, 국소적으로 줄 수 있으며 TTS의 SOTA였음
'Paper Review > Generative models' 카테고리의 다른 글
| [Paper Review] Inpaint-Anything, 2023 CVPR (5) | 2024.10.25 |
|---|---|
| Generative Adversarial Nets : GAN (1) | 2024.09.16 |
| [Paper Review] RePaint: Inpainting using Denoising Diffusion Probabilistic Models (0) | 2024.02.12 |
| Palette: Image-to-Image Diffusion Models (0) | 2024.02.04 |
| WaveNet : A Generative Model for Raw Audio (DeepMind) (0) | 2023.11.22 |


